
前言:為什麼 AI 工作流程需要評估?
在 n8n 的應用中,AI Agent 或是相關的 AI 應用一定是很多人都最有興趣,或最常使用的功能
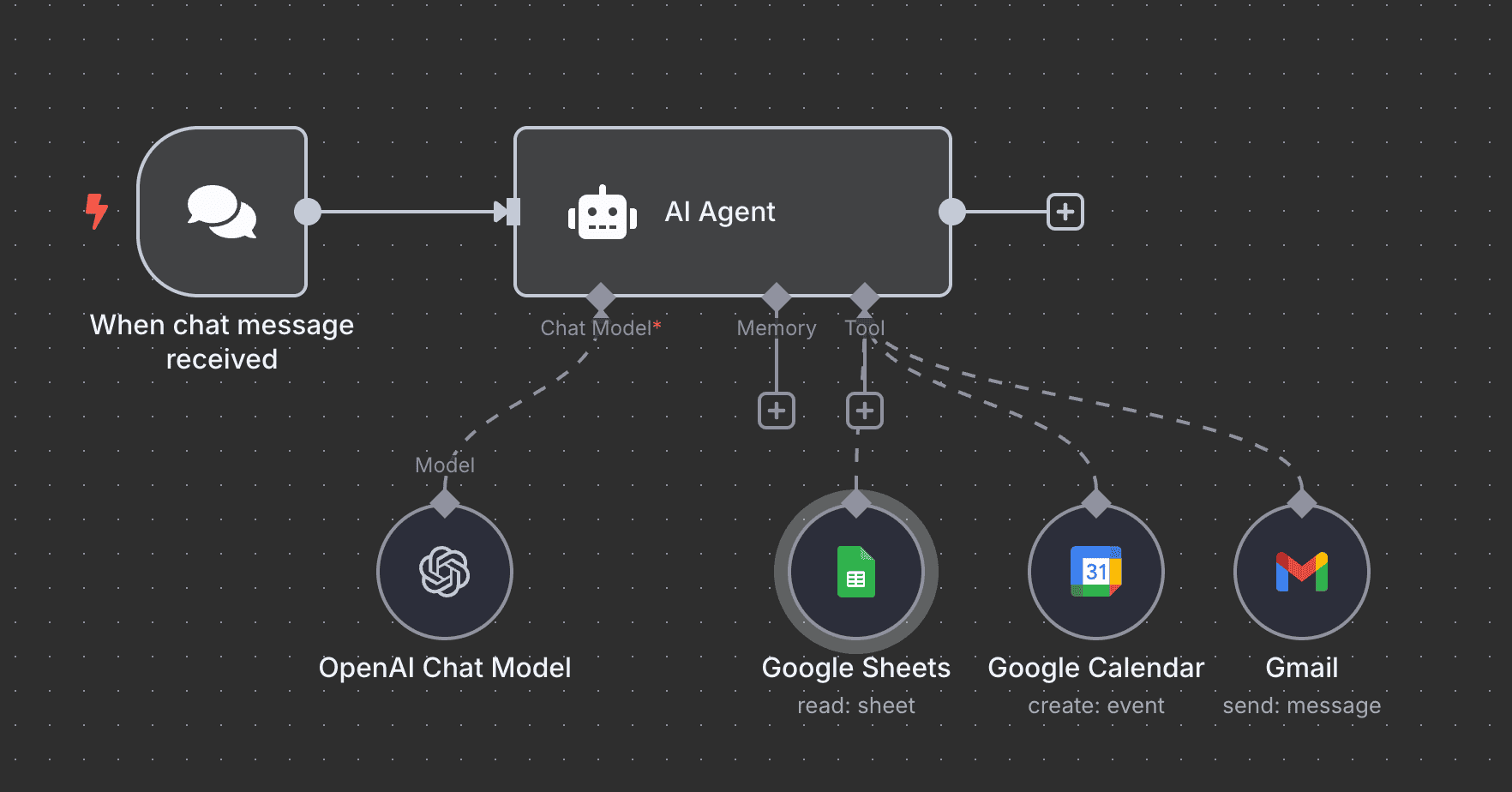
那用一陣子後你會發現,通常 AI 的節點設定完成後
後面最花時間的地方是: 一直調整 prompt 直到效果變好
是否有方法能讓我們快速測試目前 AI 的表現如何?
n8n Evaluations 是什麼?
n8n 在 1.95.1 版本中公開測試了 Evaluations
需要手動啟用!
Evaluations 啟用
打開 瀏覽器的 Devtool -> Console
貼上這段程式碼
1 | window.featureFlags.override('032_evaluation_mvp', true) |
啟用成功的話,你應該就能看到這樣的 Evaluations 在 workflow 上方
兩種評估類型
Evaluations 目前由於還在早期階段,使用上支援的方式較為單一
目前僅支援 Google Sheets 作為測試資料來源
並且你需要先輸入你的預期輸出結果
最後再跟 AI 產出的結果做個比較
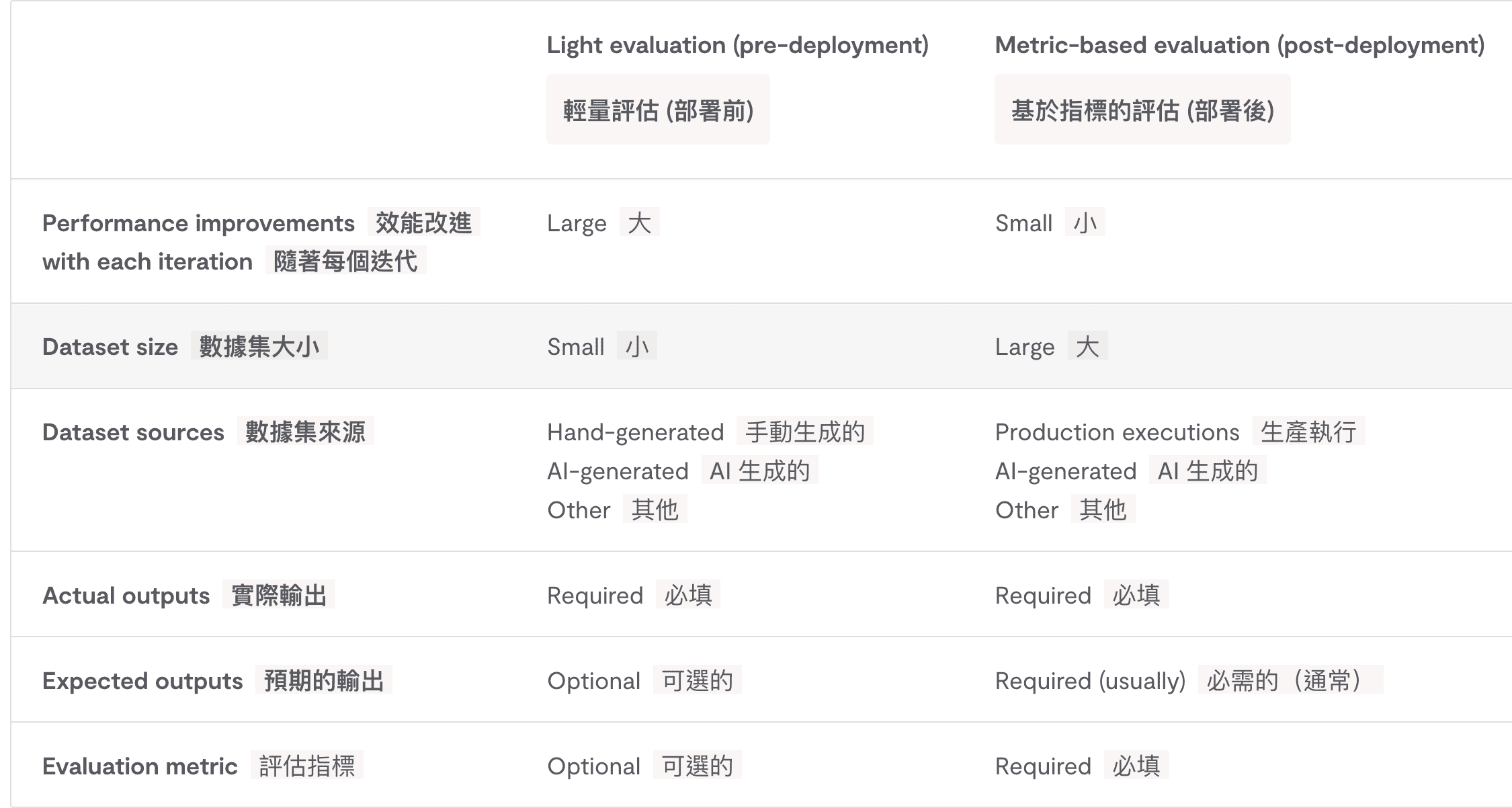
目前有兩種評估方式
1. Light Evaluations
這邊我覺得直接當作人工評估會比較好懂
適合 測試量較小的場景
給測試資料 -> 輸入預期結果 -> 等 AI 產出結果 -> 人工比較
這可以用試吃來比喻
你做出一道料理時,可能已經假設味道大概是怎樣
透過試吃來確認是否有符合預期

以這個範例說明:
我平時會透過 n8n 取得我 Threads 的文章數據表現
但現在想透過 n8n AI 來幫我產生關鍵字
所以要測試我的 prompt 是否能產出我希望的關鍵字
這個 Sheet 中我會給文章、我預期的關鍵字
執行 Evaluations 後,AI 會產出AI 關鍵字
我就可以人工觀察 AI 的產出狀況大概如何
2. Metric-based Evaluations
Metric-based 相反就適合較大型的測試資料
並且用分數指標來當作評估標準
和前面的 Light Evaluations 不同,Metric-based 會多一個分數的機制來評分
只是這個 評分 的機制也不是 n8n Evaluations 就會自己幫你打好分數
你得額外設定一個 AI 或是其他機制來評估這個分數
我的試用場景是用 AI 來評估原本的 AI 表現
延續試吃的比喻,這就不像是試吃
而是每一道料理已經有一些數值化的標準
例如 : 鼎泰豐的小籠包是 18 摺、21 公克

Evaluation Workflow 實作
前置準備
其實準備上不會太繁瑣
就是需要建立一個 Google Sheet 並貼上測試資料
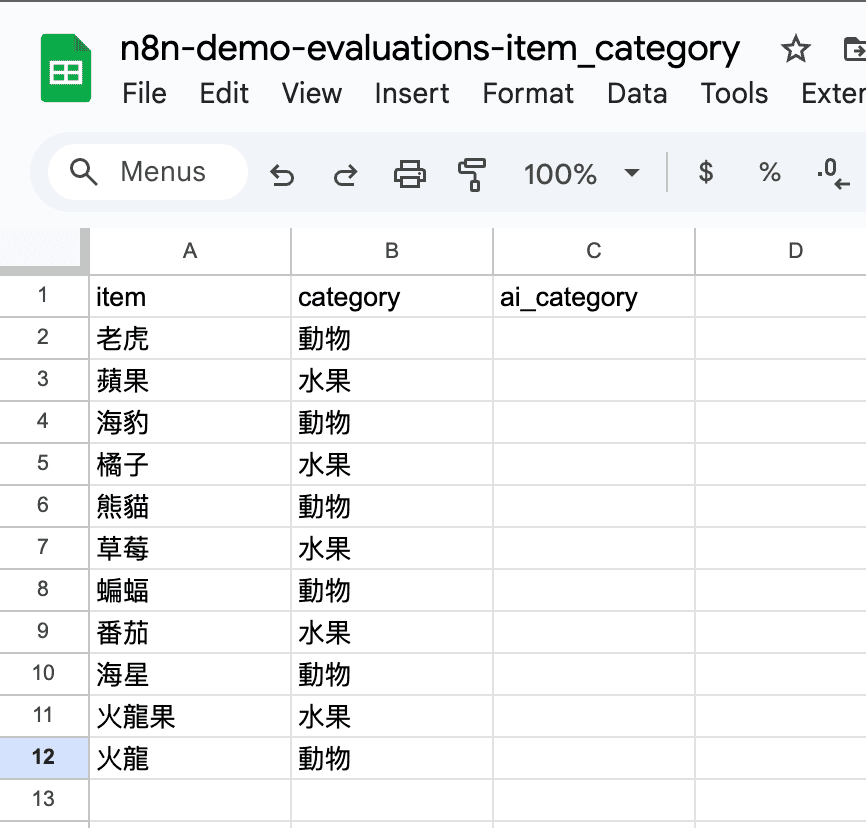
這邊提供測試的 Google Sheet
Light Evaluation Workflow
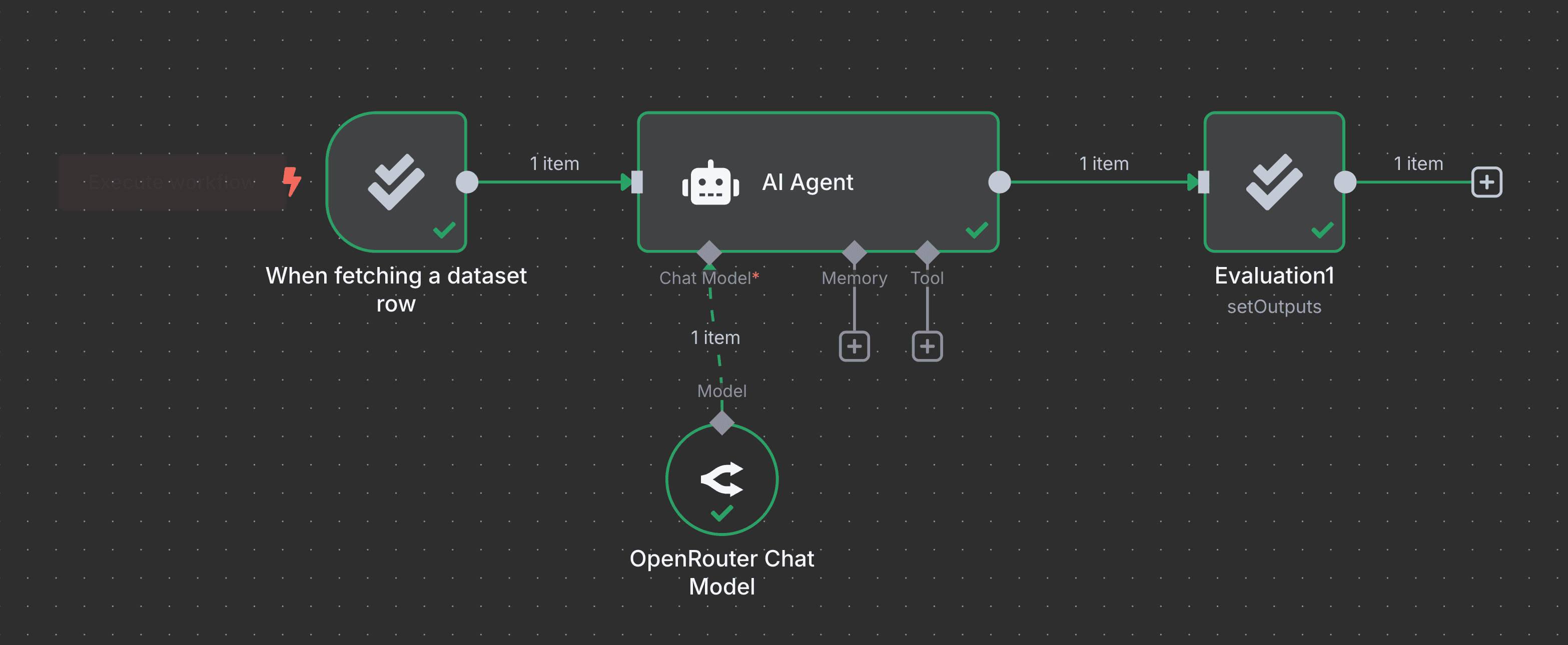
這邊提供 workflow 的 template 連結

這個 demo 非常簡單,就是讓 AI 能不能辨識正確的水果或是動物
測試時大部分的模型其實都能成功
GPT 4o-mini
GPT 4.1-nano
是特別選了一個超級小的模型才會遇到失敗
OpenRouter 的 google/gemma-3-1b-it:free
Metric-based Evaluation Workflow
這邊就先不提供測試資料和 workflow
先分享我自己的測試大概怎麼做
前面有分享一個場景是
請 AI 幫我的 Threads po文判斷關鍵字
後續我再請另一個 AI 幫忙思考前面產生的關鍵字
跟我預期的相似程度是多少

n8n Evaluations Panel
Evaluation 在社群版本中,還可以單獨用 Panel 來 run test
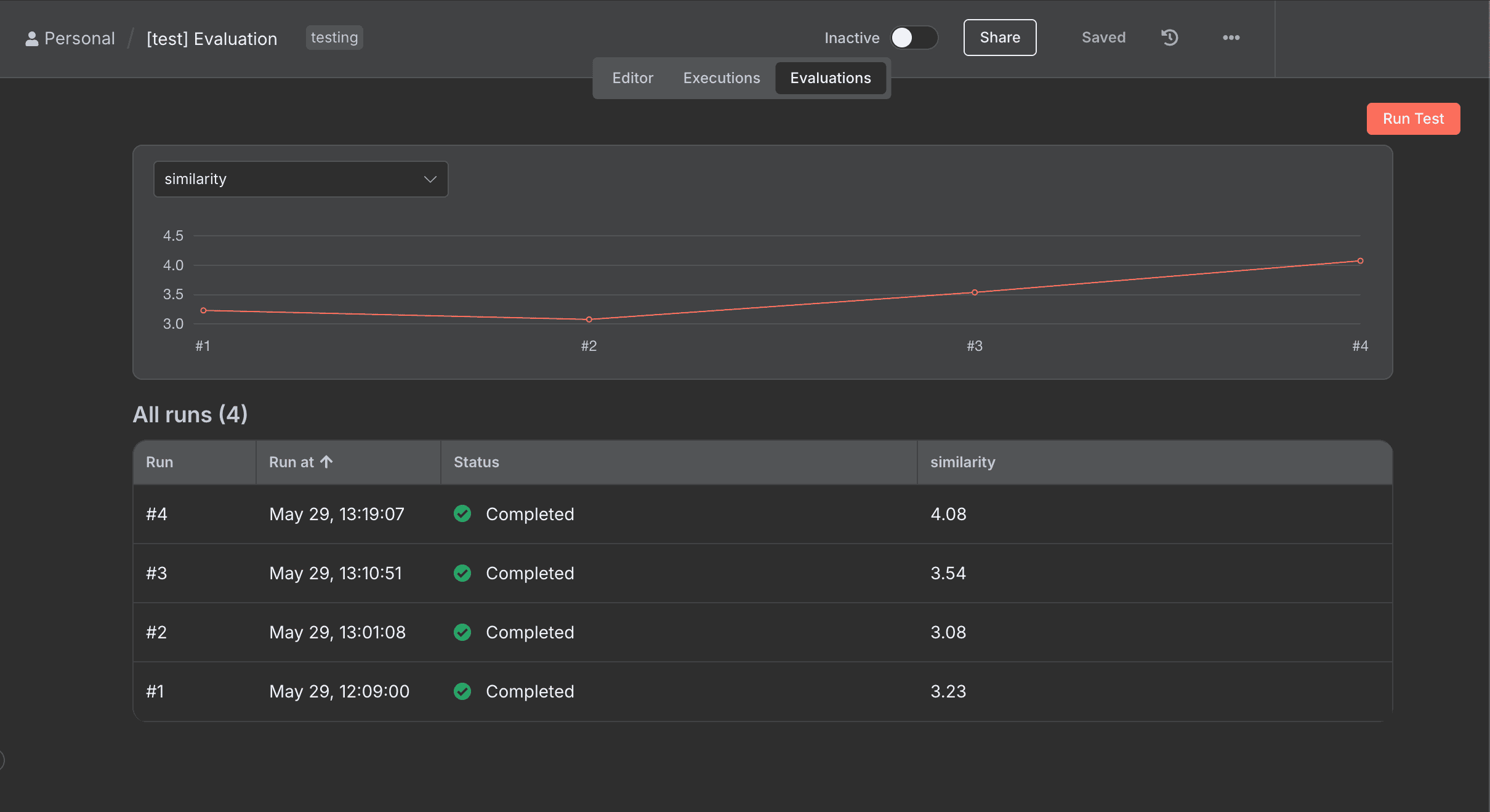
介面上會直接呈現每次 run 的時間和分數
上方也有圖表讓你觀察
更直觀的可以知道每次的調整是否真的有進步
方案限制
目前評估功能是免費的
但如果是想要使用 Evaluation Panel 來建立多個 workflow run test
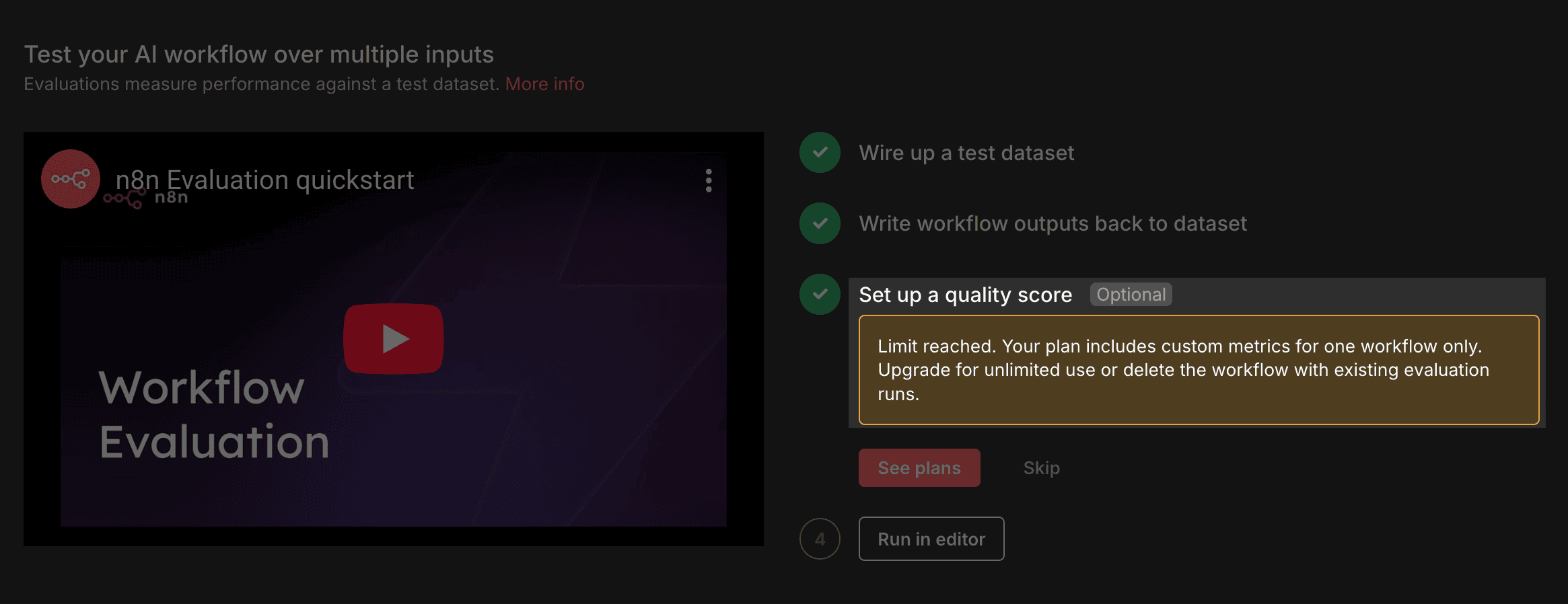
目前社群版就只能有 1 個
預計是 Pro 版本以上才會有更多的 Quota
結語
Evaluations 目前測試起來是一個不錯用的功能
可能進階的使用者以前就打造出一個 workflow 是用來評估 AI 表現的方式
這次官方直接透過 Evaluation 功能來讓大家更方便使用
目前展示的都還是簡單的 AI 場景
但在測試後,相信可以用在 AI Agent 的多 Tools 的調用能力
還有先前分享的模板 Line 國外旅遊記帳
就能更快的測試出在同樣的設定下,對於多個收據的辨識能力如何!
