
ByCrawl 節點讓你在 n8n 裡面用一把 API Key,就能抓取 Threads、Instagram、X、Reddit、Dcard、PTT 等 15 個平台的社群數據。不用每個平台各自串接 API。
預計閱讀時間: 10-12 分鐘
你將學到:
- ByCrawl 的「一次爬取各大平台」核心概念
- 社群節點安裝與 API Key 設定
- Resource(選平台)+ Operation(選操作)的使用方式
- 實戰案例:品牌聲量監控自動化
如果趕時間,可以跳到
你有沒有遇過這種情況?
想要監控品牌在社群上的討論,但 Threads 要串一個 API、X 要串一個、Reddit 又是另一個。
每個平台的 API 格式都不一樣,光是搞認證就搞到頭痛。
更麻煩的是,有些平台根本沒有開放 API。
像 Dcard、PTT 這種台灣本土論壇,想要自動抓資料只能自己寫爬蟲。
ByCrawl 就是來解決這個問題的。
一把 API Key 搞定 15 個平台,回傳的資料格式也統一,不用再對每個平台的 API 文件。
ByCrawl 是什麼?
ByCrawl 是一個爬蟲資料 API 平台,串接一次後就能取得 15 個平台以上的資料。
不管你要抓 Threads Instagram 的貼文和帳號資料、還是 Dcard 的討論,或是 PTT 的貼文,都只要註冊一次服務就好。
ByCrawl 主打 15 個社群、論壇、商家平台,另外附贈 Google SERP 和 Web Fetch 兩個通用 API:
- Threads
- Facebook(含 Marketplace)
- X / Twitter
- TikTok
- LinkedIn(含職缺搜尋)
- YouTube(含字幕)
- Dcard
- PTT
- Product Hunt
- Hacker News
- Google Maps
- Trustpilot
- 104 人力銀行
- 591 租屋網
- Google SERP(Google 搜尋結果、新聞、Trends)
- Web Fetch(抓任意公開網頁、Brave Search)
另外還有 Luma(活動日曆)API,這篇教學主要聚焦在社群和通用爬蟲。
跟 Apify 有什麼不同?
如果你看過我之前寫的 Apify 教學,可能會有點好奇他們的不同。
Apify 是爬蟲的平台,上面有幾千個 Actor,但你得自己去找哪個 Actor 適合你。同一個平台可能有 5-10 個不同的 Actor 甚至更多,品質參差不齊,有些資料不是你要的、有些收費超級貴,光是挑選和測試就要花不少時間。
ByCrawl 不一樣,它把所有平台的 API 都整合好了。你不用挑 Actor,直接選好平台就能馬上取得資料
| 比較項目 | ByCrawl | Apify |
|---|---|---|
| 定位 | 整合好的社群 API,開箱即用 | 爬蟲市集,要自己挑 Actor |
| 上手成本 | 選平台 → 選操作 → 拿資料 | 找 Actor → 比較 → 測試 → 設參數 → 等爬蟲跑完 |
| 回傳速度 | 通常 1-5 秒 | 看 Actor,可能 30 秒到幾分鐘 |
| 資料格式 | 所有平台統一格式 | 每個 Actor 格式不同 |
| 台灣常見平台 | ✅ Dcard、PTT、104、591 | ❌ 幾乎沒有 |
| 計費方式 | Credit 制(按 API 呼叫) | 按運算時間 + 資料量 |
簡單來說:
- 要爬社群數據,想馬上能用,特別是台灣平台 → ByCrawl
- 要爬電商、新聞、或需要複雜客製化爬蟲 → Apify
Credit 怎麼計算?
ByCrawl 用 Credit 計費,每個 API 呼叫扣不同的點數。
大部分操作落在 2-4 Credit,各類型參考如下:
| 操作類型 | Credit 消耗 |
|---|---|
| 一般查詢(Threads / Reddit / Dcard / PTT) | 2-3 pt |
| Instagram / X / TikTok 查詢 | 2-4 pt |
| LinkedIn 使用者 / 公司 | 3-4 pt |
| 搜尋類(按筆計費) | 2-3 pt / 筆 |
| YouTube / TikTok 字幕 | 4 pt |
大部分操作都落在 2-4 Credit,預算很好抓。搜尋類是「每筆 x Credit」計費,要多拉筆數前先估一下總量。
社群節點安裝與 API Key 設定
Step 1:安裝 ByCrawl 社群節點
在 n8n 左下角的設定圖示,點進去找到 Community nodes:
點選 Install,輸入套件名稱:
@bycrawl/n8n-nodes-bycrawl
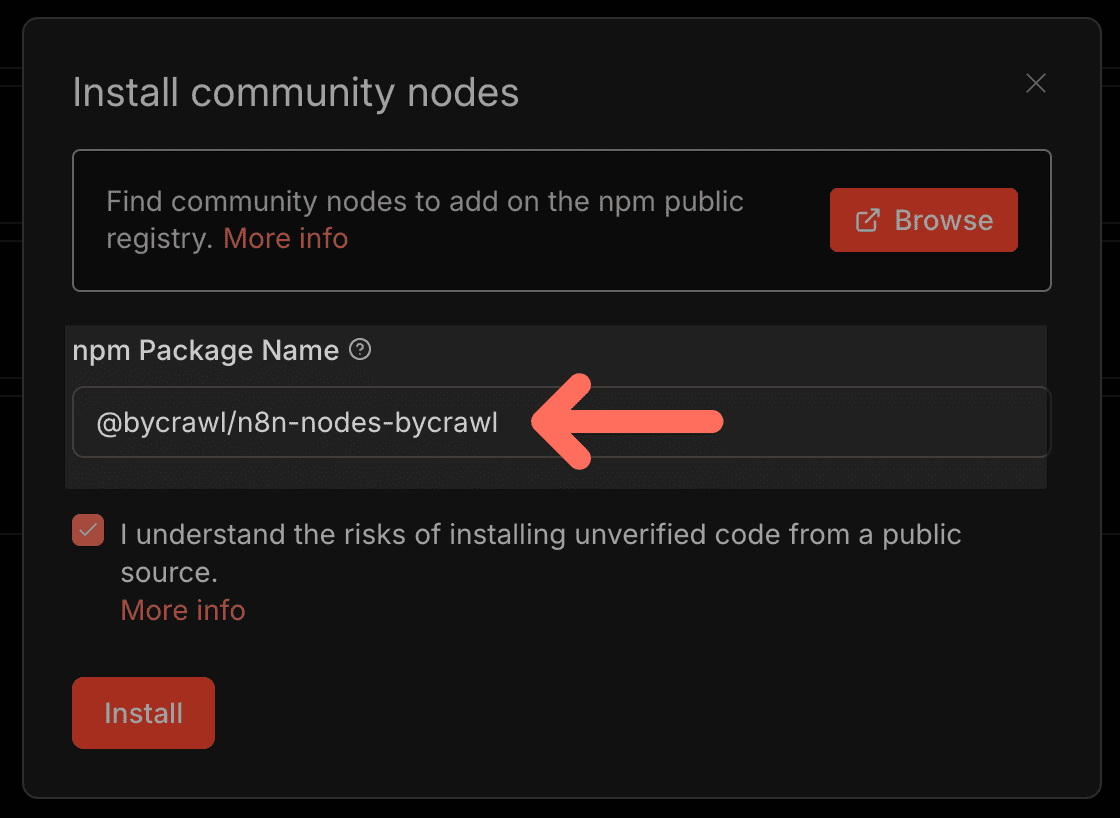
勾選同意後按 Install,等幾秒就裝好了。
Step 2:取得 ByCrawl API Key
- 到 ByCrawl 註冊帳號(有 7 天免費試用)
- 登入後進到 API Keys 頁面複製 API Key(格式是
sk_byc_開頭)
Step 3:在 n8n 設定 Credential
在 workflow 裡拉一個 ByCrawl 節點,點 Credential 的「Create New」:
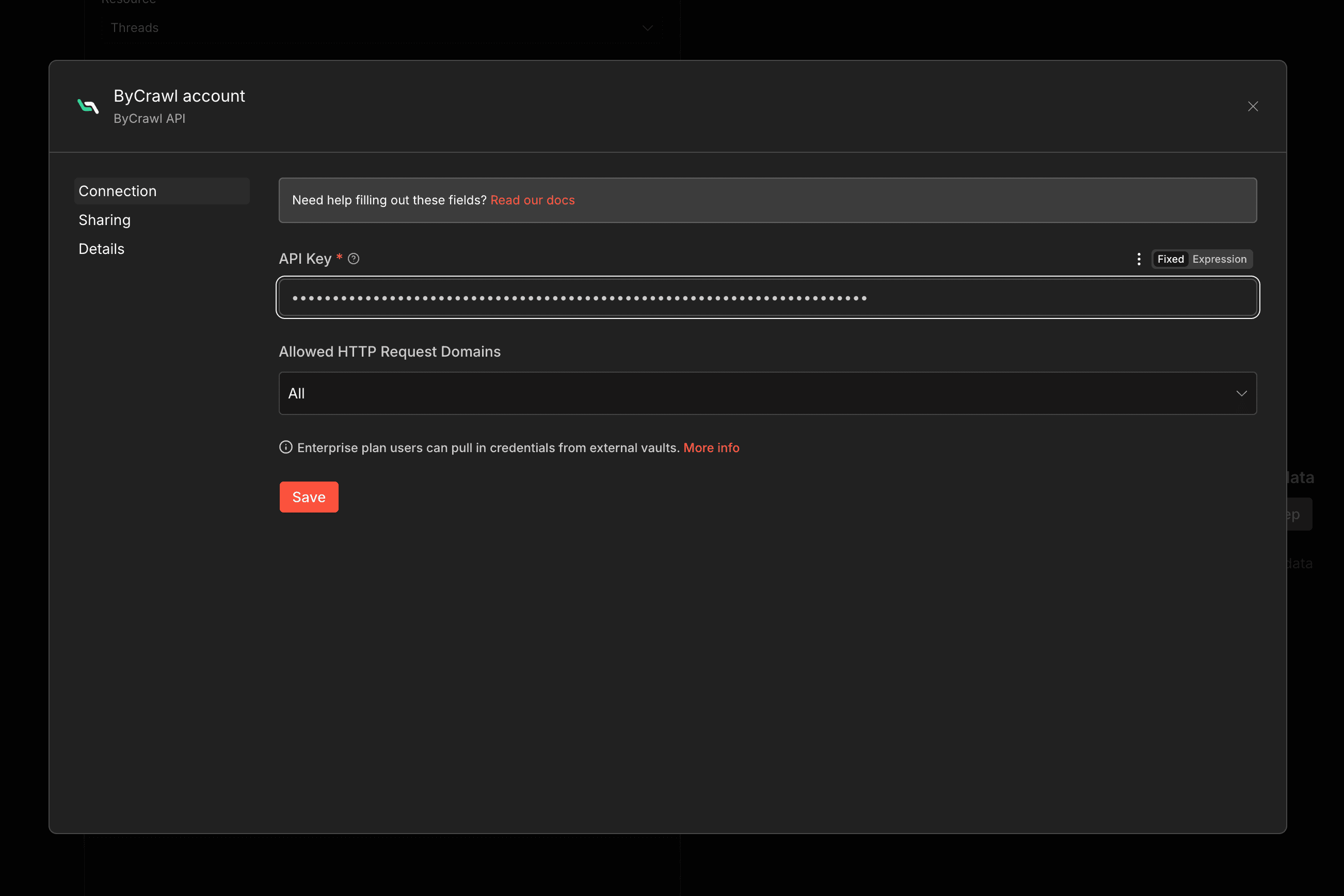
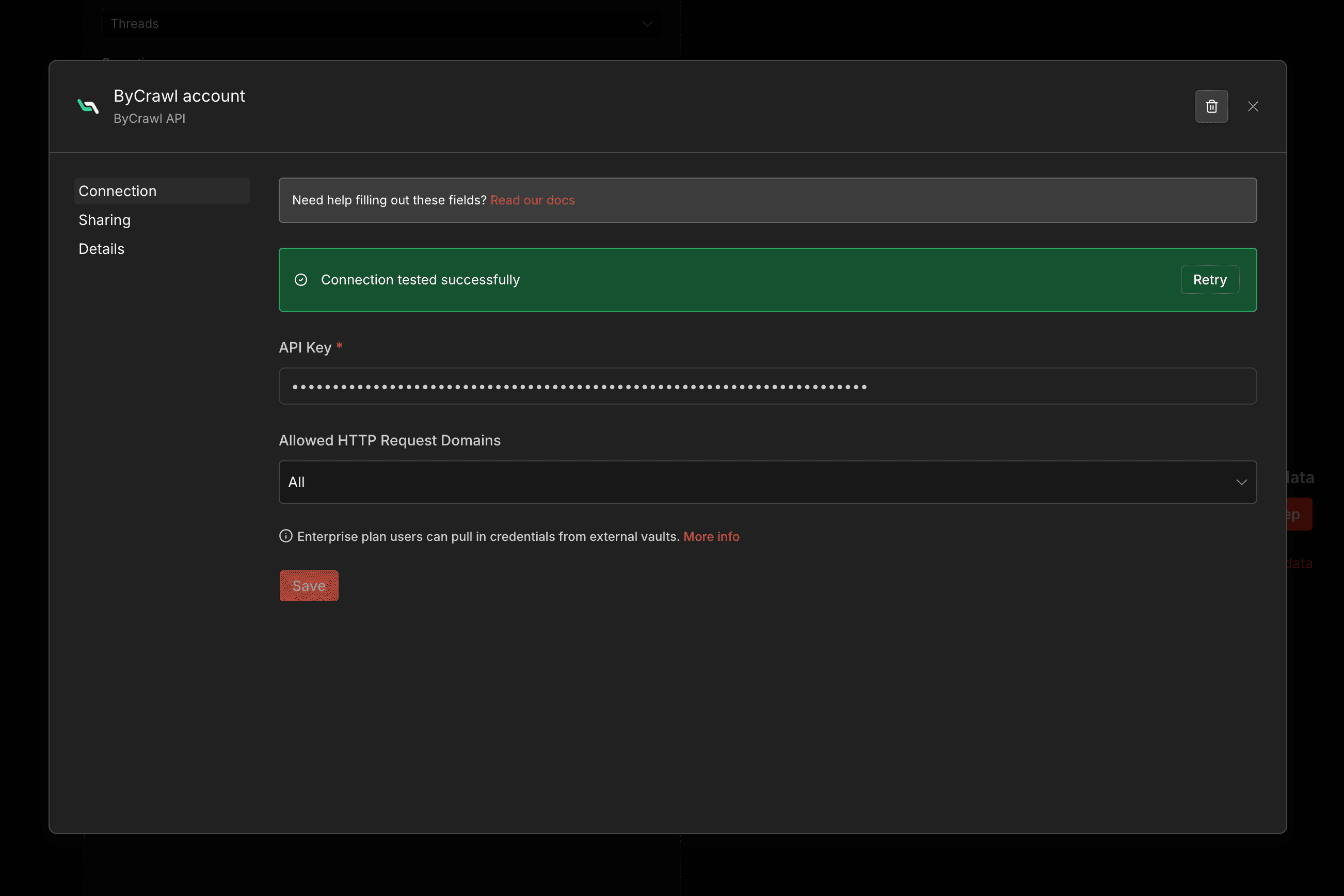
貼上 API Key 後按 Save,看到綠色的「Connection tested successfully」就完成了:
ByCrawl 節點功能介紹
ByCrawl 節點的操作邏輯是:先選平台(Resource),再選操作(Operation)。
一個節點就能切換 15 個平台,不用裝 15 個不同的節點。
Threads — 取得使用者資料
最基本的操作,選 Resource 為 Threads,Operation 為 Get User,輸入 username 就能拿到 profile:
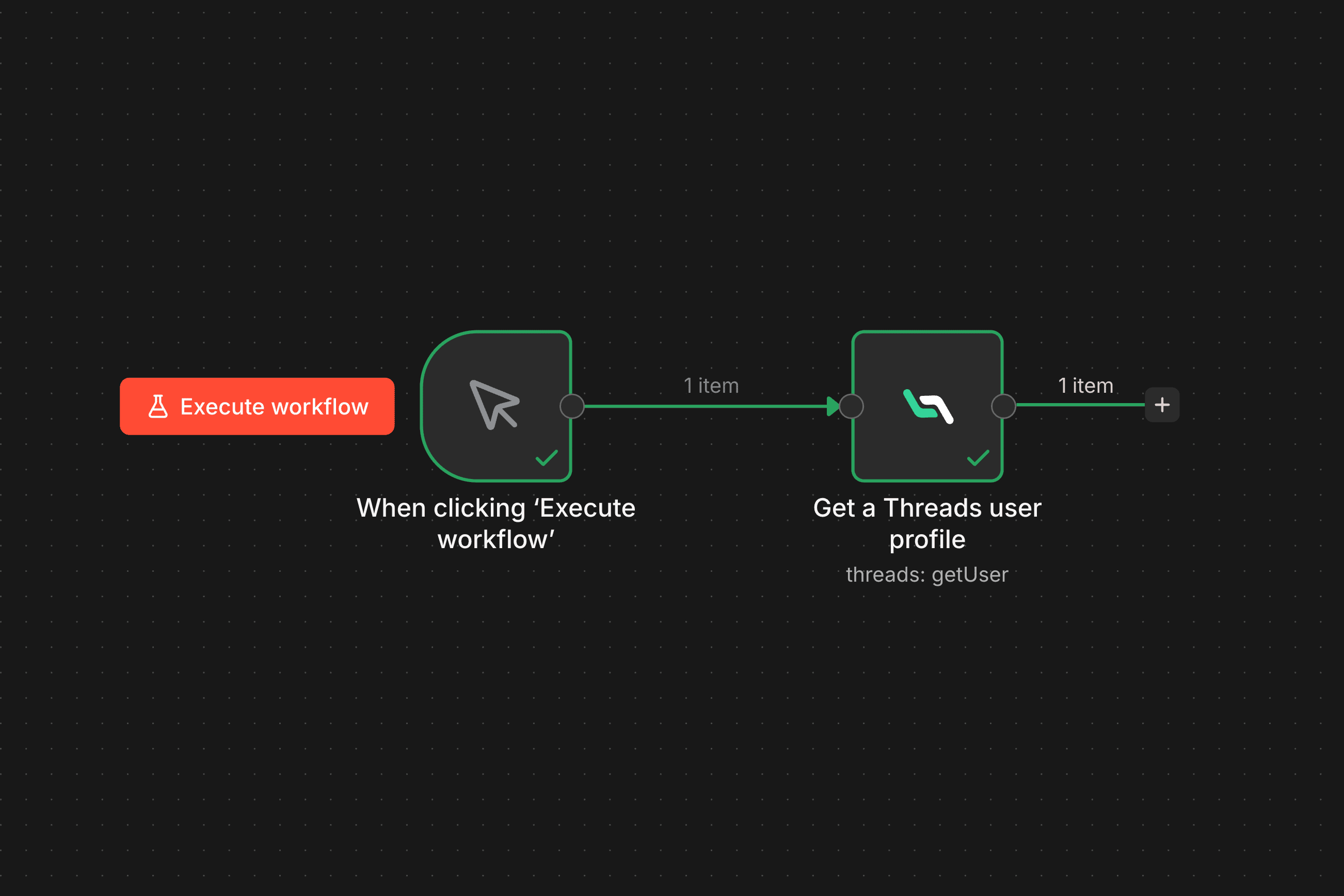
回傳的資料包含:username、fullName、bio、followerCount、followingCount、isVerified 等等。
Instagram — 取得帳號資料與貼文
Instagram 的 Get User 比 Threads 更豐富,一次呼叫就能拿到 profile 加上近期貼文:
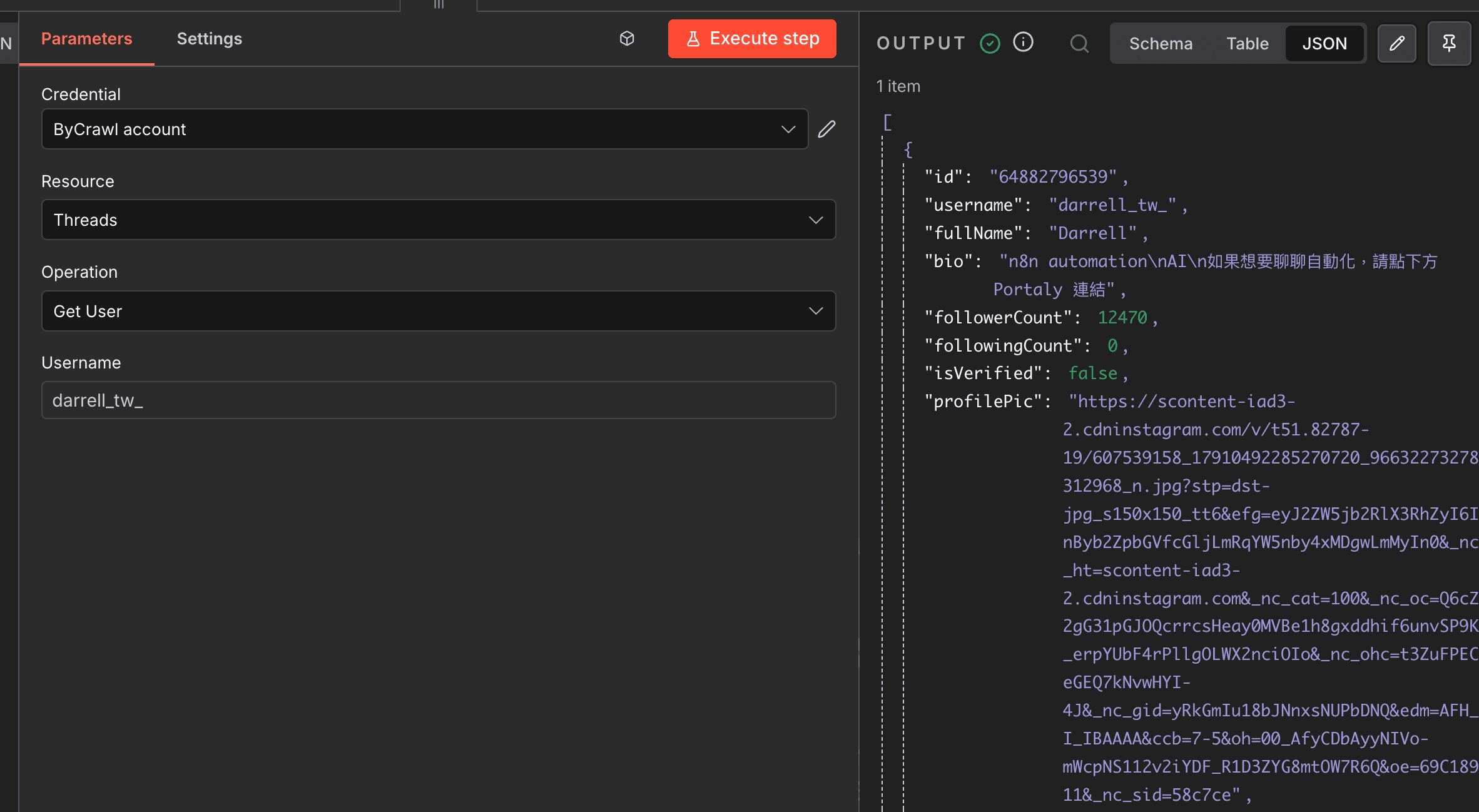
不需要 Meta 的官方 API 授權,就能拿到別人帳號的公開資料。這是 ByCrawl 最大的優勢之一。
各平台支援的操作一覽
每個平台支援的操作不太一樣,整理如下方便查詢:
1 | 社群 / 論壇 |
591 租屋的 region(地區)和 kind(類型)已經做成中文下拉選單了,不需要自己查代碼對照表,蠻貼心的。
台灣常見平台實測
ByCrawl 最大的賣點是台灣平台支援(Dcard、PTT、104、591)。實際抓起來品質如何?我用關鍵字「n8n」(591 是台北市整層住家)各打一次 curl 看看:
| 平台 | 單次筆數 | 總量提示 | 資料新鮮度 | 速度 | Credit |
|---|---|---|---|---|---|
| Dcard | 30 | 無 | 2025-10 最新貼文 | 0.33s | 2 pt |
| PTT(Gossiping) | 10 | prev/next page | 當日貼文 | 1.04s | 2 pt |
| 104 人力銀行 | 10 | totalCount 194 | 2026-04-17(3 天內) | 1.19s | 2 pt |
| 591 租屋網 | 10 | total 3,712 | 「3 小時內更新」 | 1.75s | 2 pt |
幾個實測心得:
- 資料密度夠高:104 光「n8n」關鍵字就 194 筆職缺、591 台北市套房 3,712 筆,拿來做監控、全量爬都夠用
- 更新夠即時:PTT 抓到當日貼文、591 標記「3 小時內更新」,代表 ByCrawl 是即時爬不是快取
- PTT 需要指定看板:不能跨板搜尋,要追 Gossiping、Tech_Job、Stock 就要開 3 個節點
實戰案例:品牌聲量監控
這個案例展示如何每天自動搜尋品牌關鍵字,跨 4 個平台收集提及,用 AI 分析情緒,最後輸出到 Slack 和 Google Sheets。
流程: Schedule Trigger(每日 09:00)→ Config 設定關鍵字 → 4 個 ByCrawl 節點平行搜尋 → Code 合併資料 → AI 情緒分析 → Slack + Google Sheets
Workflow 架構
完整的 workflow 大概是這樣:
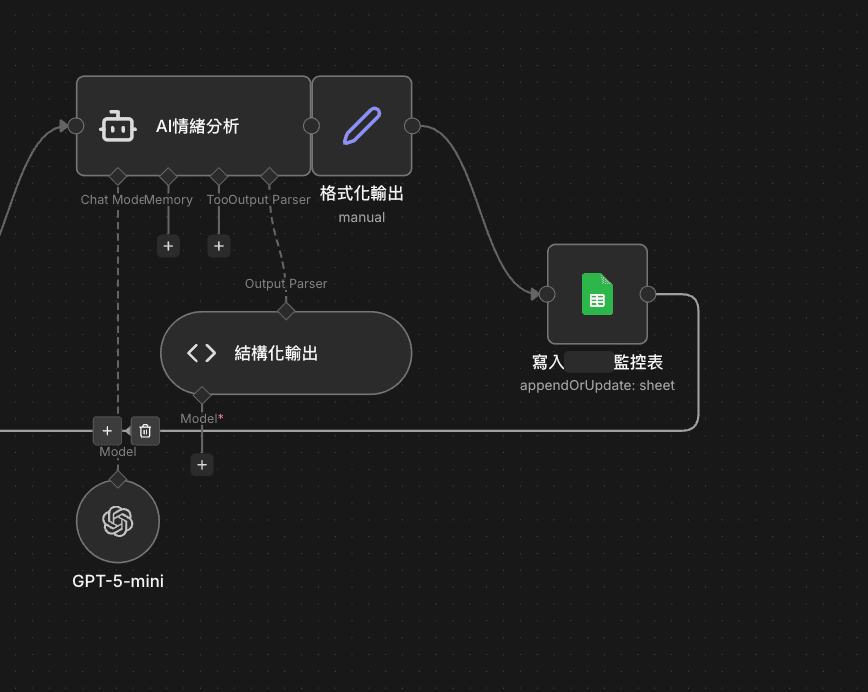
前半段是 Schedule Trigger → Config → 4 個 ByCrawl 節點(Threads / X / Reddit / Dcard)平行搜尋,後半段是 AI 情緒分析 → 格式化輸出 → Slack + Google Sheets。
下面這張是後半段的截圖,AI 分析完後寫入 Google Sheets:
核心設計
4 個 ByCrawl 節點平行搜尋,每個都開啟「錯誤時繼續執行」,這樣某個平台掛掉不會影響其他平台,整個 workflow 不會因為一個 API 錯誤就停掉。
AI 分析用 OpenAI gpt-5-mini,prompt 要求輸出:
- 情緒分佈(正面/中性/負面比例)
- 互動數最高的 3 則貼文
- 一句話趨勢總結
每日成本預估
| 平台 | Credit | 說明 |
|---|---|---|
| Threads Search | 3 pt | 搜尋約 15 筆 |
| X Search(10 筆) | 30 pt | 3 pt/tweet,最貴的部分 |
| Reddit Search | 2 pt | 最多 25 筆 |
| Dcard Search | 3 pt | 最多 30 筆 |
| 合計 | ~38 pt/天 | 每月約 1,140 pt |
X 的搜尋是按 tweet 計費(3 pt/tweet),佔了大部分成本。如果預算有限,可以把 x_count 調低或直接關掉 X 搜尋。
定價方案
| 方案 | 月費 | 每月 Credit | 適合 |
|---|---|---|---|
| Lite | $9 USD | 1,000 | 試用、單一用途 |
| Pro | $29 USD | 5,000 | 日常品牌監控 |
| Power | $79 USD | 15,000 | 多場景、高頻使用 |
| Elite | $159 USD | 30,000 | 企業級、全平台監控 |
以品牌聲量監控為例,每天約 38 Credit,一個月 1,140 Credit,剛好超過 Lite 方案($9 / 月)的 1,000 Credit 額度一點點。
超額以 Credit 計費,各方案超額費率不同(Lite 約 $0.012 / credit、Pro 約 $0.006 / credit),可以依實際用量估算。
不會寫程式也能上手嗎?
雖然 ByCrawl 本身已經把 API 包得很簡化,但整套品牌聲量監控 workflow(Schedule + Config + 4 個 ByCrawl 平行搜尋 + AI 分析 + Slack / Google Sheets)對完全沒碰過 n8n 的行銷人員來說還是有門檻。
不過用 n8n 的好處會是一但建立起來後,後續的維護和調整會比較方便。
如果是用 AI vibe coding 一套來實作,還要看看自己對於 server 維護部署是否熟悉。
另外未來如果要增加功能或是調整,AI 在改 code 的時候往往有 bug 的機率也會稍微高一點。
想要類似的爬蟲服務但沒有工程資源,也可以 找我實作和討論
什麼時候不該用 ByCrawl?
ByCrawl 蠻方便的沒錯,但也有些限制要注意:
節點無法翻頁
目前 byCrawl 社群節點的介面不支援設定分頁參數,每次搜尋只能拿到第一批結果(通常 15-30 筆)。需要翻頁的話,要把 ByCrawl 節點換成 HTTP Request 節點,在 URL 帶分頁參數(Dcard / Threads 用 offset、Reddit 用 after)直接打 ByCrawl API。
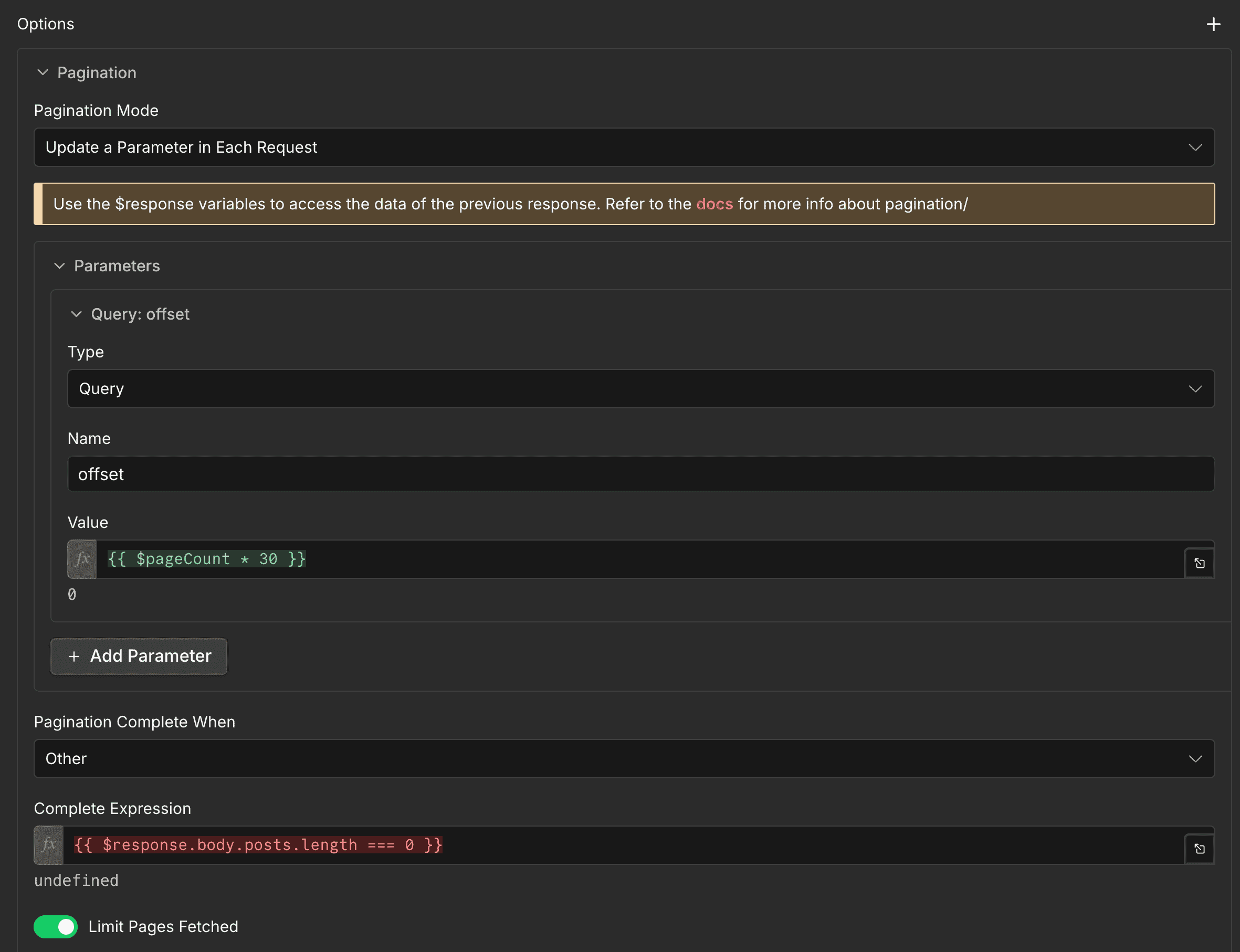
把 ByCrawl 節點換成 HTTP Request 節點,base URL 是 https://api.bycrawl.com。
Authentication:Generic Credential → Header Auth,Name 填 x-api-key、Value 填 sk_byc_...(注意:不是 Authorization: Bearer,ByCrawl 用的是 x-api-key header)
翻頁:在 HTTP Request 節點的 Options → Pagination 設定,Mode 選「Update a Parameter in Each Request」:
對大多數監控場景來說,第一批結果已經夠用。
部分平台速度較慢
TikTok 和某些 Dcard 操作,單次呼叫需要 10-40 秒;一般搜尋類操作大多 1-5 秒(我實測 Dcard Search 只要 0.3 秒)。在 workflow 裡記得把 timeout 調到 120 秒,避免 n8n 提早中斷。
X 取最新推文要用 Search
這個是實測才發現的坑。用 Get User Posts 抓某個帳號的推文會拿到「熱門推文」(按互動排序,可能是好幾年前的舊文),不是最新的。要拿最新推文必須改用 Search Posts,query 設為 from:USERNAME、Product 選 Latest。
如果只是要抓自己帳號的數據,建議用各平台的官方 API。ByCrawl 的優勢是抓別人的公開資料,或是那些沒有開放 API 的平台(Dcard、PTT、591 等)。
我實測踩過的坑
以下都是我打 curl 跑過一輪之後記錄的,ByCrawl 文件沒寫清楚、但實際用會撞到的細節。
1. 各平台 pagination 機制不同
想在 n8n 跨平台翻頁,得自己 switch case:
- Dcard / Threads:
?offset=N - Reddit:回傳
after欄位 → 下次帶?after={值} - PTT / 104:
?page=N&count=N - 591:
?first_row=N
2. 時間欄位結構不統一
- PTT:
date: "4/20"(只有月日,沒年份) - 104:
appearedAt: "20260414"(YYYYMMDD 字串) - Dcard:
createdAt: "2025-10-21T11:08:12.512Z"(ISO 8601) - 591:
refreshTime: "3小時內更新"(人類可讀字串,要 parse)
跨平台合併資料前,記得加一個 Set 或 Code 節點統一時間格式,不然排序會亂。
3. Auth header 用 x-api-key 最保險
實測 Authorization: Bearer 也能通,但官方文件只列 x-api-key。認官方的就好,免得未來出現其他問題或是錯誤。
curl 快速驗證範本(給想跳過 n8n 直接測 API 的人)
不想先裝 n8n、想確認 ByCrawl API 是不是真的能抓到你要的資料?把下面指令複製到 terminal 就能測(記得把 API Key 換成自己的)。這整套指令我都實測跑過:
先設定 API Key:
1 | export BYCRAWL_API_KEY='sk_byc_你的_key' |
1. 抓 Threads 用戶資料(~2 Credit)
1 | curl -H "x-api-key: $BYCRAWL_API_KEY" \ |
2. 搜尋 Dcard 貼文(~3 Credit)
1 | curl -H "x-api-key: $BYCRAWL_API_KEY" \ |
3. Dcard 翻頁(offset-based,從第 31 筆開始)
1 | curl -H "x-api-key: $BYCRAWL_API_KEY" \ |
4. 搜尋 Reddit(注意回傳的 after 欄位是翻頁 cursor)
1 | curl -H "x-api-key: $BYCRAWL_API_KEY" \ |
5. Reddit 翻頁(把上一次的 after 值帶進來)
1 | curl -H "x-api-key: $BYCRAWL_API_KEY" \ |
6. 搜尋 Threads 貼文(~3 Credit / 筆)
1 | curl -H "x-api-key: $BYCRAWL_API_KEY" \ |
上面 6 個指令全部跑過一輪大約用掉 15-25 Credit,7 天免費試用期間跑這輪綽綽有餘。jq 只是拿來美化 JSON 輸出,沒裝也能跑(回傳會是一整串 JSON)。
常見問題
相關文章推薦



總結
ByCrawl 最大的價值就是超級方便
一把服務就能拿到 15 個以上平台的資料,對於需要跨平台監控社群的人來說,省掉非常多串接的時間
特別是台灣的使用者,Dcard、PTT、104、591 這些平台的支援是其他爬蟲工具很少看到的
對於這些平台爬蟲資料有興趣的使用者都可以試試看
如果需要專案建置或是做成週報月報也可以找我聊聊
有任何 ByCrawl 相關問題歡迎在下方留言!