
Apify 節點讓你在 n8n 中直接調用現成的爬蟲,自動爬取 TikTok、Instagram、Youtube 等等資料,完全不用自己從頭開始寫程式。
預計閱讀時間: 8-10 分鐘
你將學到:
- Apify 的 Actor(爬蟲程式)和 Dataset(資料集)核心概念
- API Token(金鑰)申請與 n8n Credentials(憑證)設定
- Run Actor 和 Scrape Single URL 實際操作
- 案例:Instagram 競爭對手數據自動同步到 Google Sheets
如果趕時間,可以跳到
你有沒有遇過這種情況?
想要定期追蹤競爭對手的社群數據,但每次都要手動複製貼上
更麻煩的是研究了 API 文件後卻發現,根本做不到!
像是 Meta API 只能取得自己帳號的數據。
況且這些平台也都會有很嚴格的反爬蟲機制,
就算是學過基礎的爬蟲,也會發現很難取得自己想要的資料。
Apify 可以解決很多爬蟲的痛點
Apify 是什麼?
他是個爬蟲的平台,你可以想像成 App Store 或 Google Play。
大家可以把自已做好的爬蟲(應用程式)上傳到 Apify。
在 Apify 中他不是叫做 App,它叫做 Actor(演員,但在這裡指的是「爬蟲程式」)
更有趣的是,同一種爬蟲會有多個相似的 Actor
每個 Actor 之間會因為熱門的程度或是功能的差異,而有不同的計算價格方式。
Apify 可以爬哪些網站?
- TikTok
- Threads
- X (Twitter)
- Youtube
- Amazon
- Google Maps
Actor = 爬蟲程式
Actor 可以想像成「外送平台上的餐廳」,當你想要取得一份餐點時:
- 先選餐廳(資料的平台,像是 Instagram、Youtube 等等)
- 選擇餐點(選擇 Actor,例如爬貼文還是爬帳號)
- 付款下單(設定參數並執行)
- 等餐點送到(等待爬取結果)
Dataset = 爬取的資料
每次 Actor 執行完,結果會存放在 Dataset(資料集)中。
像是一個 暫存的資料表,資料會保留 7 天讓你取用。
7 天是免費方案的預設值。如果你需要更長的保留時間,可以在 Actor 設定中調整 datasetRetentionDays 參數,或升級付費方案。
Apify vs HTTP Request:什麼時候用哪個?
如果你不知道 HTTP Request 是什麼,可以先跳過這段,直接看設定教學。
| 情境 | 推薦 | 原因 |
|---|---|---|
| 爬取靜態網頁 | HTTP Request | 簡單直接,不需額外費用 |
| 爬取需要 JavaScript 渲染的頁面 | Apify | 內建 headless browser(無頭瀏覽器) |
| 爬取有反爬機制的網站 | Apify | 內建 proxy(代理伺服器)和反偵測 |
| 爬取社群平台 (Meta/X) | Apify | 專門的 Actor 已處理好複雜邏輯 |
API Token 申請與 n8n 設定
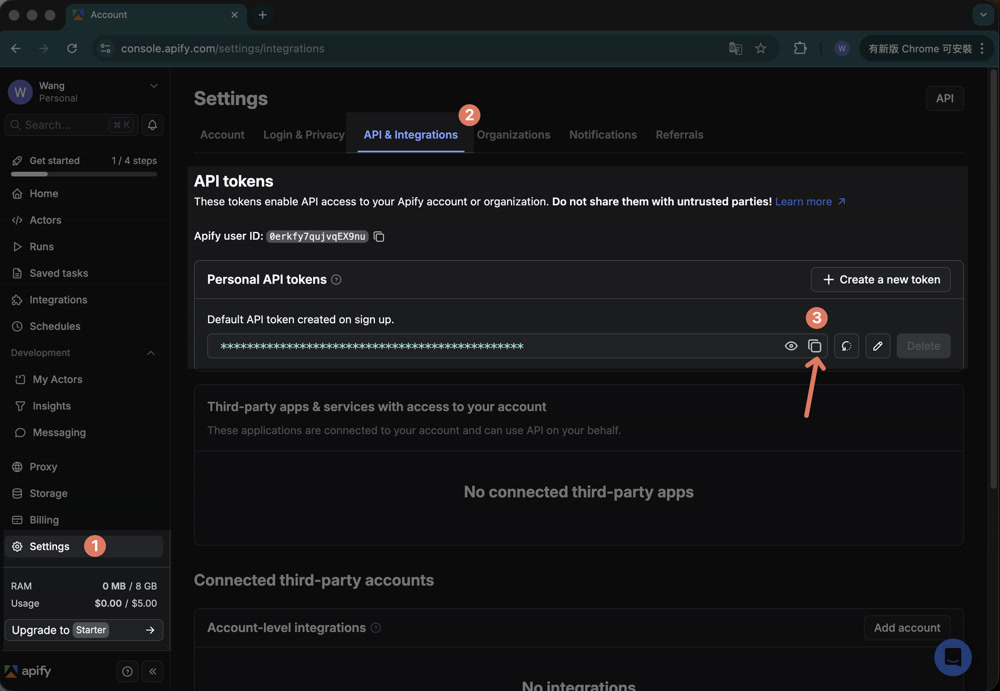
Step 1:取得 Apify API Token
API Token(API 金鑰)是讓 n8n 能夠連接到你的 Apify 帳號的通行證。
- 到 Apify Console 註冊帳號(免費方案每月有 $5 USD 額度,不用綁信用卡)
- 進入 Settings > API & Integrations
- 在 Personal API tokens 複製 token
Step 2:在 n8n 設定 Credentials
Credentials(憑證)是 n8n 用來儲存各種服務帳號資訊的地方。
- 在 n8n 左側選單進入 Credentials(憑證)
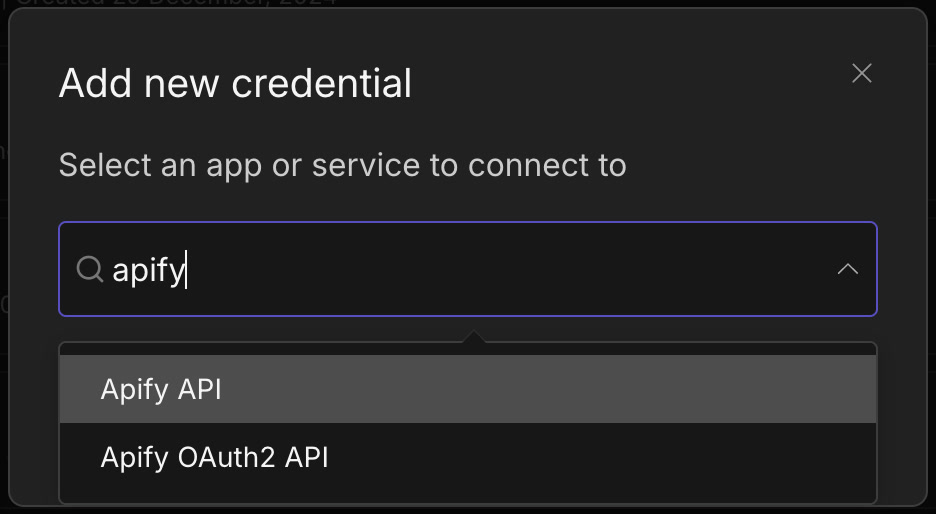
- 點選 Add Credential(新增憑證)並搜尋「Apify API」
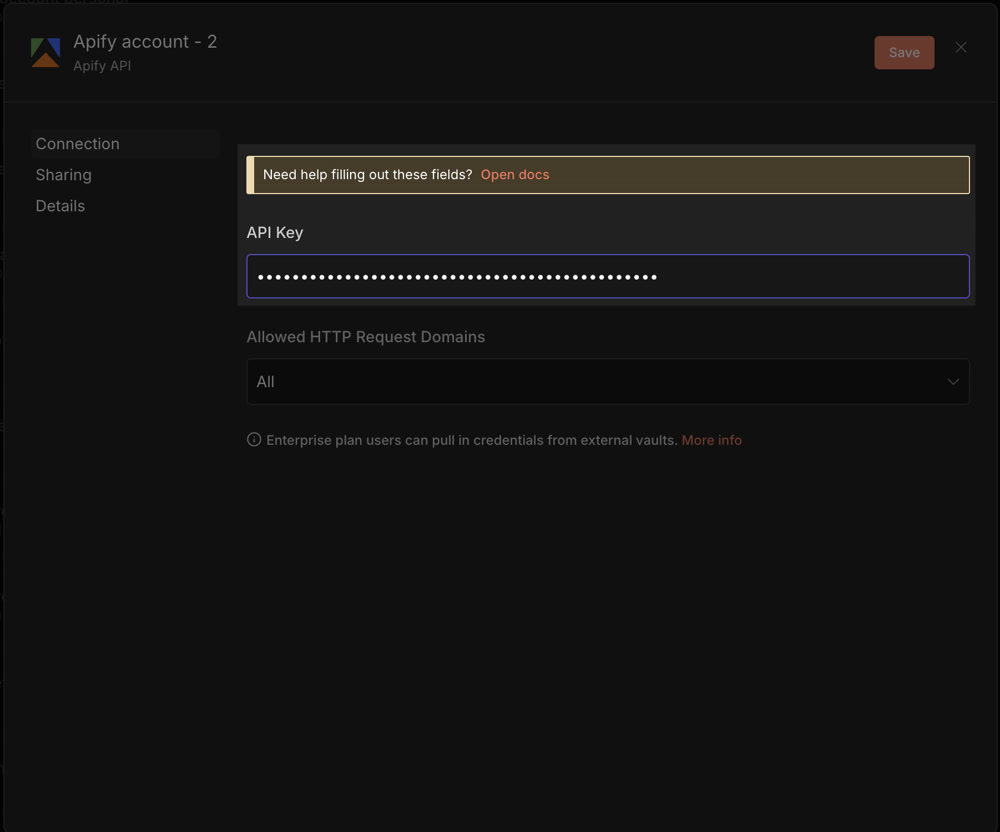
- 貼上剛才複製的 API Token
- 點 Save 後測試連線
相關文件可以參考 Apify n8n 整合文件。
n8n Apify 節點功能介紹
Apify 的 n8n 節點提供蠻多操作,
但我們挑選三個最常用的功能來介紹。
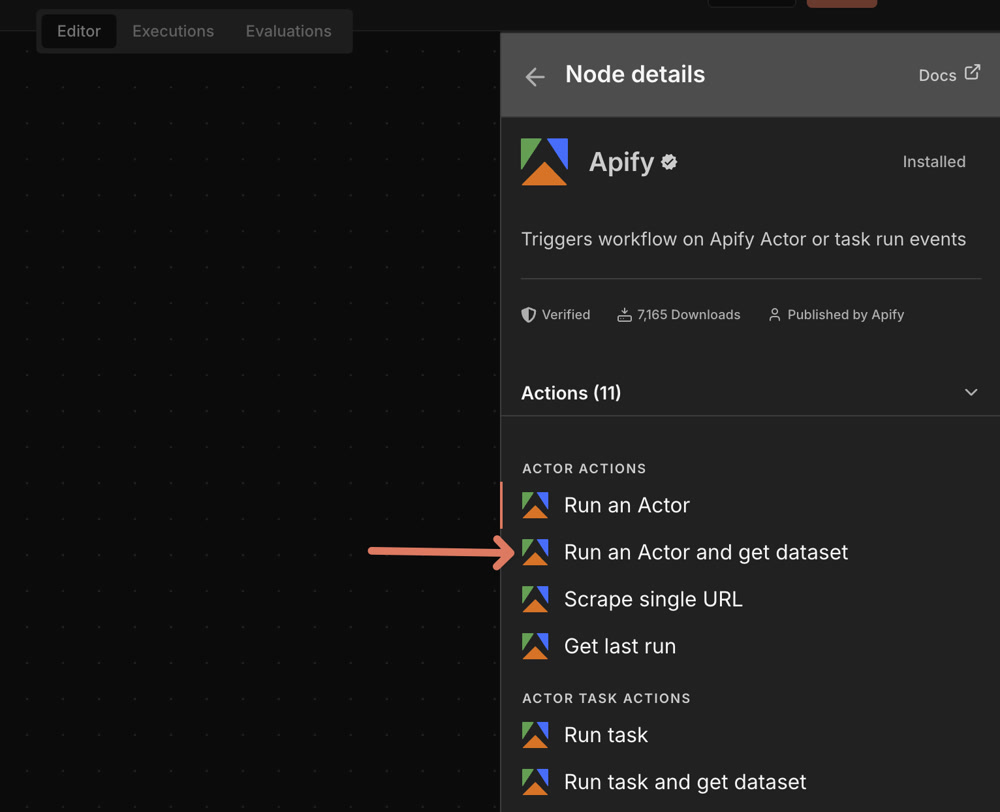
Run Actor and get dataset items
這是最常用的操作——啟動 Actor、等它跑完、直接拿結果,一步到位。
使用場景:
- 定時爬取社群數據
- 收集競爭對手資訊
- 取得特定關鍵字的 LinkedIn 職缺
參數說明:
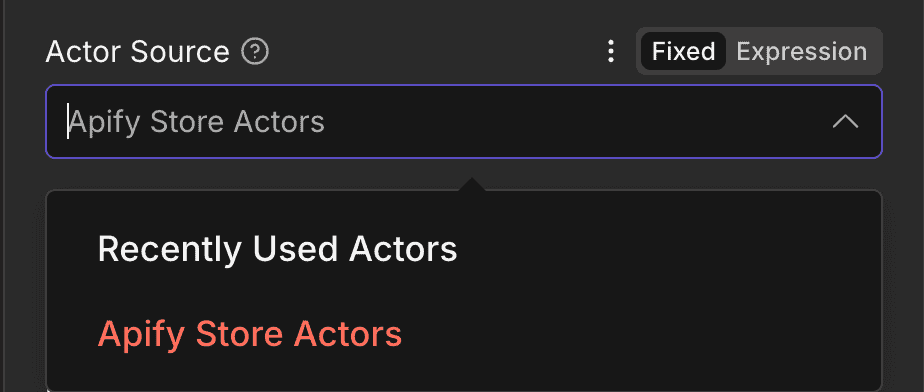
- Actor Source:有兩種!
- Apify Store Actors
可以用名字直接搜尋所有的 Actor - Recently Used Actors
只會顯示最近使用過的,例如你在 Apify 網頁版先試跑過的 Actor
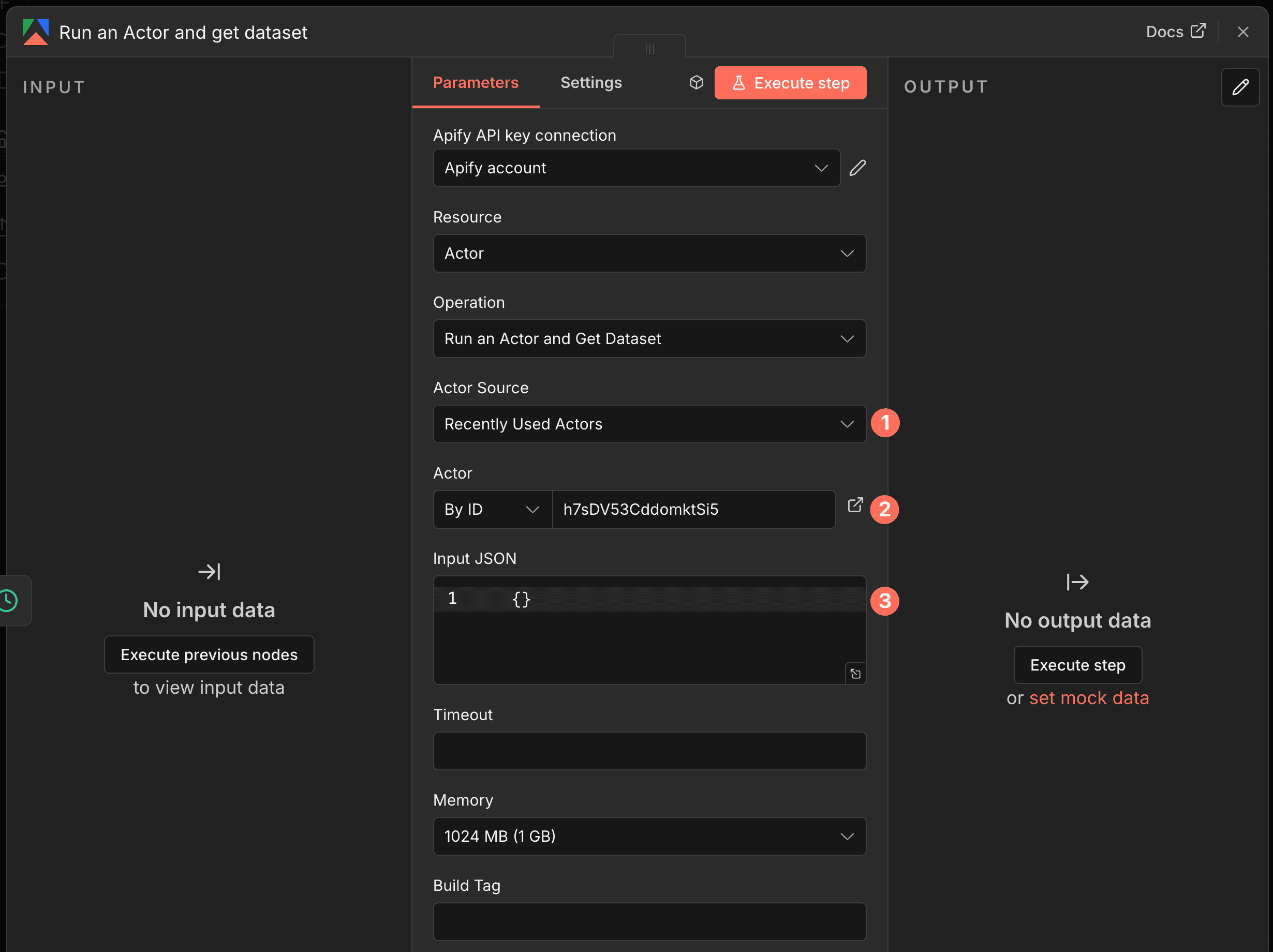
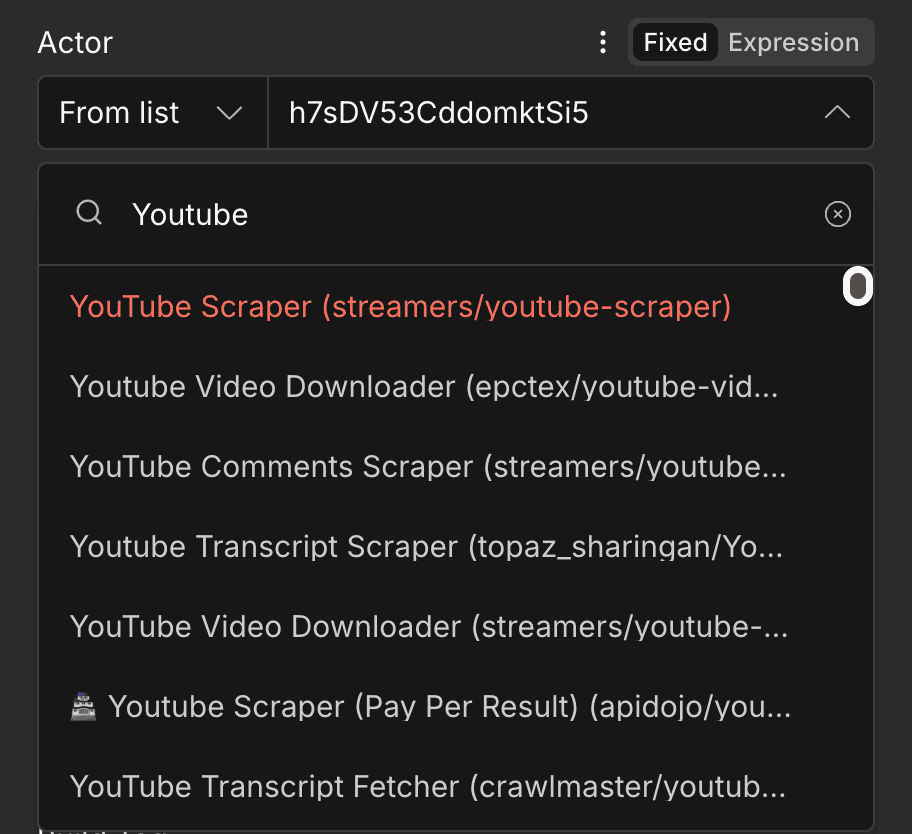
- Actor:
如果用 ID 的話取得比較麻煩:
點開 Actor 後,在 URL 中可以找到 ID,格式像https://console.apify.com/actors/{{actor_id}}/
以這個例子為例
https://console.apify.com/actors/h7sDV53CddomktSi5/input
當中的 h7sDV53CddomktSi5 就是 ID
也可以直接用 list 來選或是搜尋喔
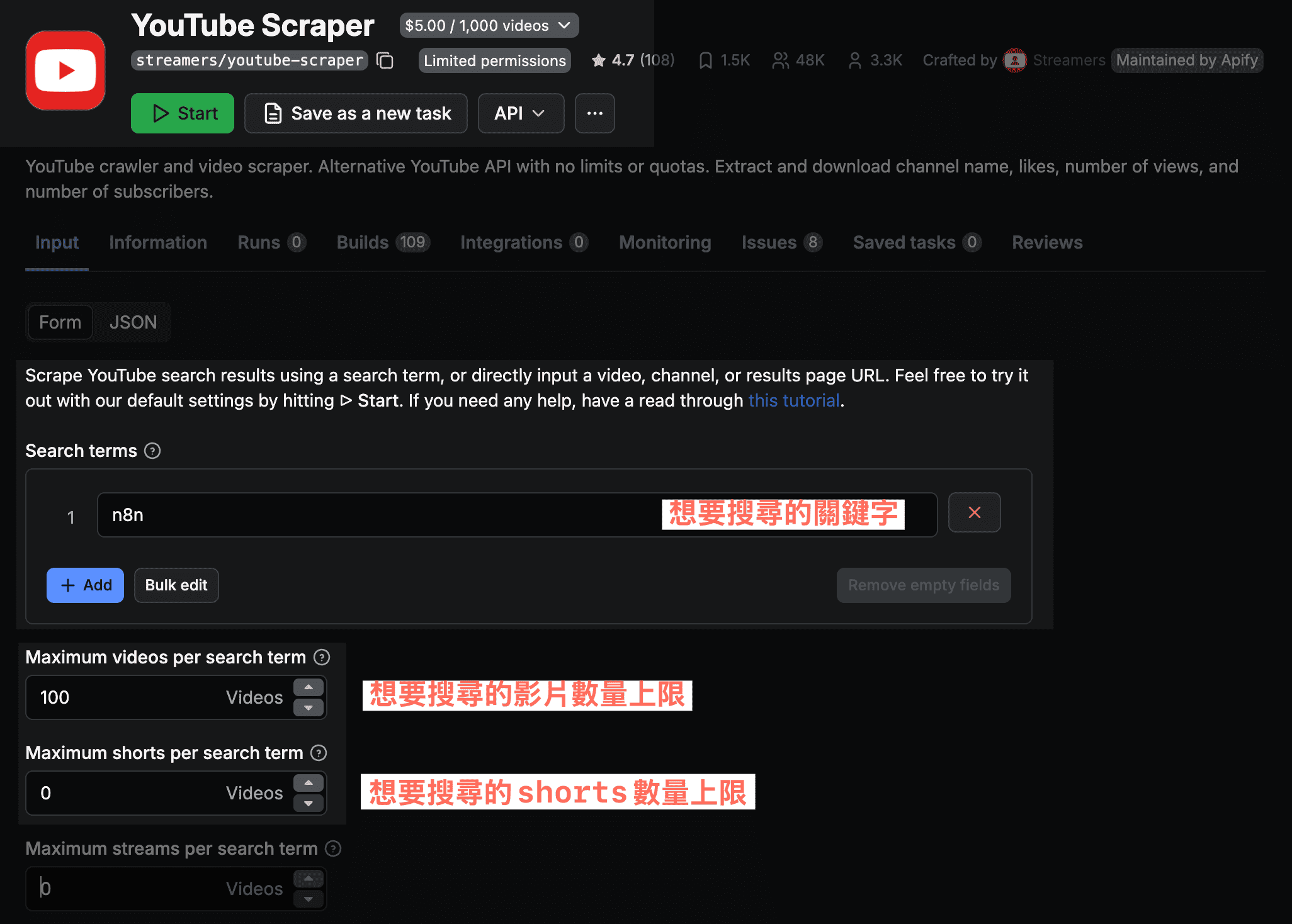
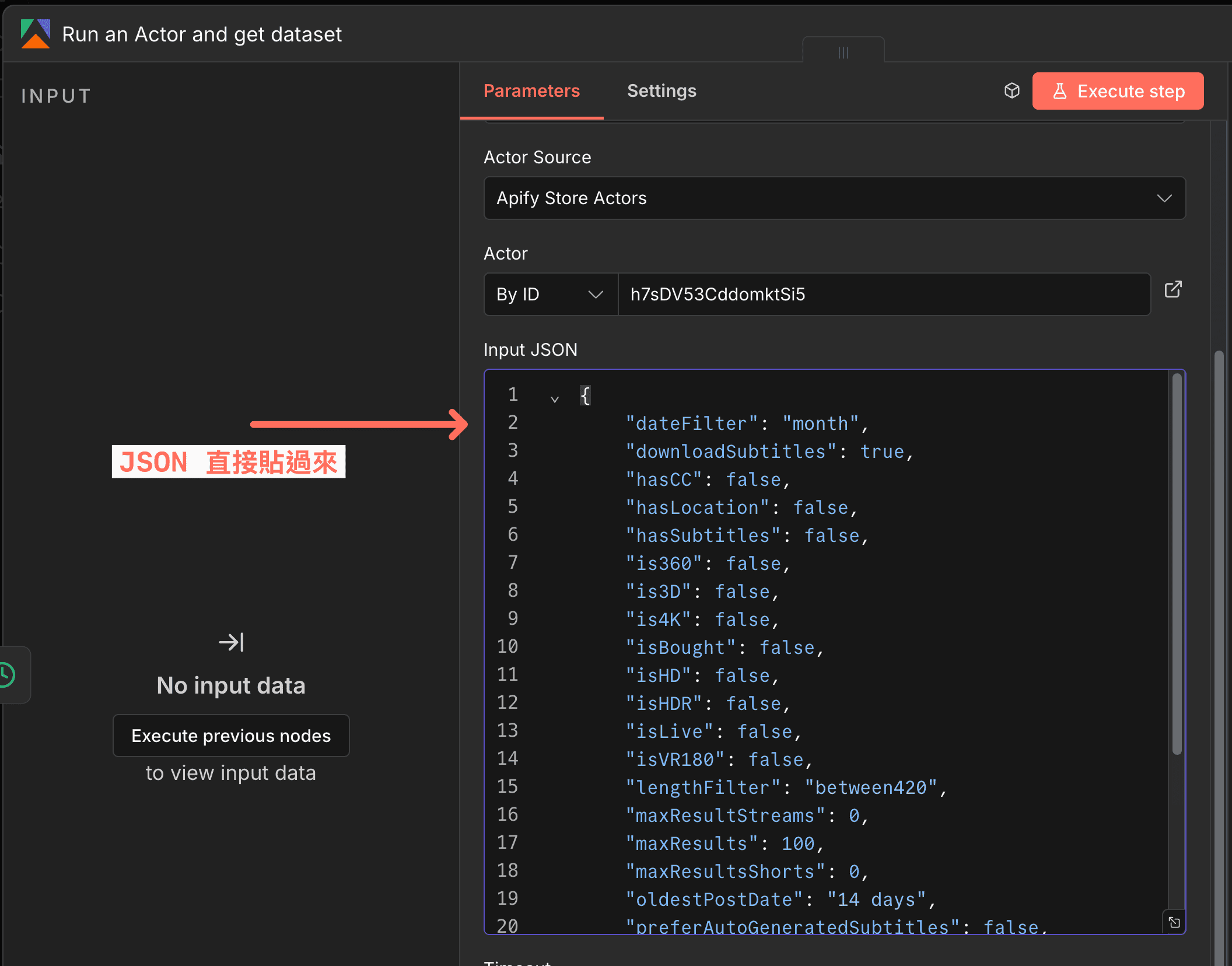
- Input JSON:Actor 需要的 JSON(一種資料格式)參數
通常我的習慣都會是在 Apify 根據 Actor 的說明先測試
舉例這是一個 YouTube Scraper,在 Apify 網頁版可以先試跑看看參數怎麼設定:
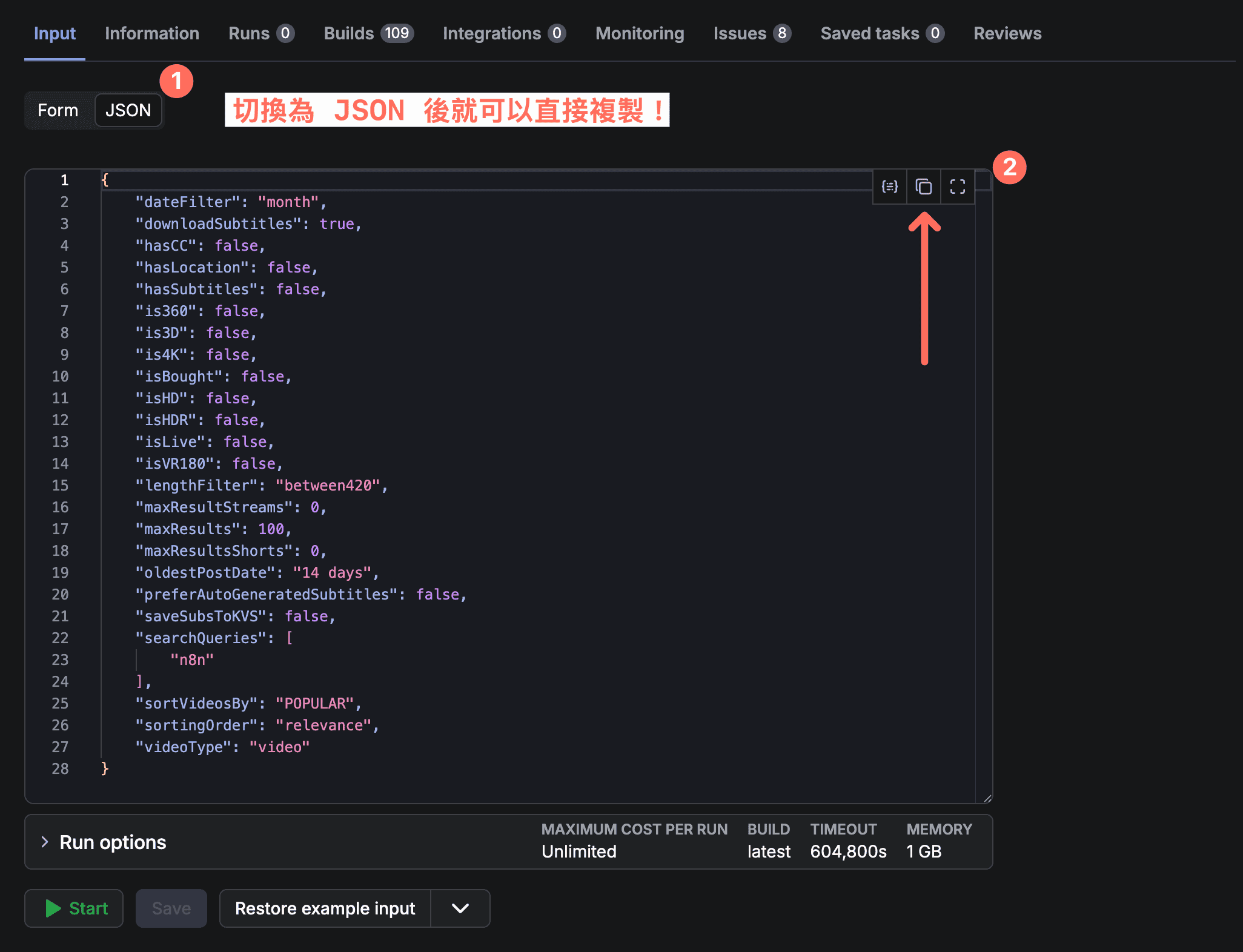
測試成功後,把相同的 JSON 貼到 n8n 的 Input JSON 欄位:
如果 Actor 執行失敗,n8n 會顯示錯誤訊息。常見原因:
- Input 參數格式錯誤:檢查 JSON 是否有多餘的逗號或引號
- 額度用完:到 Apify Console 查看剩餘額度
- Actor 本身不穩定:換一個類似功能的 Actor 試試
建議在 Workflow 中加入 Error Workflow 來處理失敗情況。
Scrape Single URL
這個其實是用 Apify 內建的 Website Content Crawler 來爬取單一頁面,會把內容轉成 Markdown 或 HTML。
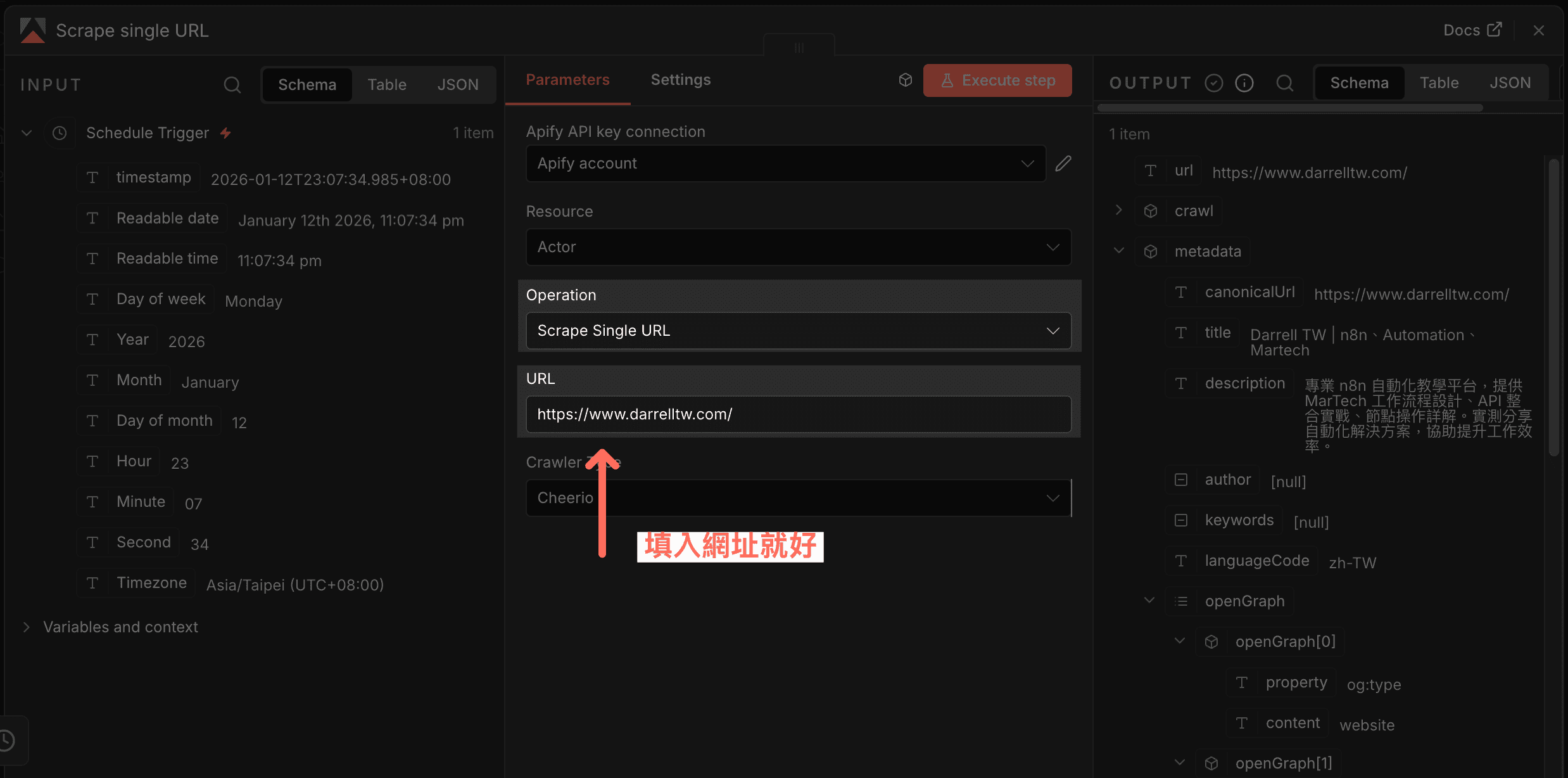
適合場景:
- 新聞文章
- 部落格文章
跟 Actor 的差異在哪?
這個功能適合靜態網頁,他通常會需要自己處理 HTML 的 DOM 結構
例如我要的新聞標題在 div 的什麼 class 裡面
新聞內容在哪個 div 底下的 p 元素
如果要爬社群平台,還是建議用專門的 Actor。
Run Actor(進階用法)
跟上面不同的是,這個只負責「啟動」Actor,不會等它跑完。
什麼時候用?當 Actor 執行時間很長(例如爬幾千筆資料),可以搭配 Apify Trigger 來接收完成通知。
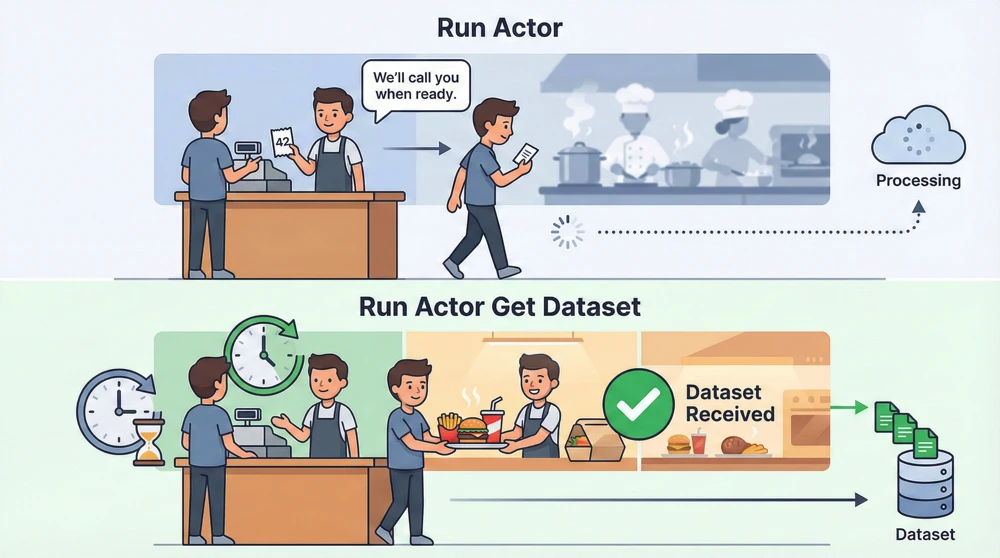
舉個例子:
你去餐廳點餐時,如果是付完錢在旁邊等候餐點完成,這樣子就像是 Run Actor and get dataset items
但是如果他有給你一個感應器,會在餐點完成時發出通知,那就像是 Run Actor + Apify Trigger 的組合,
你手中拿的感應器就是一個 Webhook(網址回呼,當事情完成時自動通知你的機制)。
當你需要爬取大量資料(例如 1000 筆以上),Actor 可能會執行超過 5 分鐘。這時候用 Run Actor and get dataset items 可能會 timeout(逾時)。
正確做法:
- 用
Run Actor啟動爬蟲 - 設定
Apify Trigger節點監聽完成事件 - 完成後自動觸發後續處理
這樣可以避免 Workflow 卡住,也能處理更大量的資料。
n8n Apify 實戰案例:Instagram 競爭對手追蹤
這個案例展示如何每週自動爬取競爭對手的 Instagram 貼文數據,並同步到 Google Sheets 做分析。
流程: Schedule Trigger(排程觸發器,設定每週自動執行)→ Apify Run Actor → Set Node 整理資料 → Google Sheets
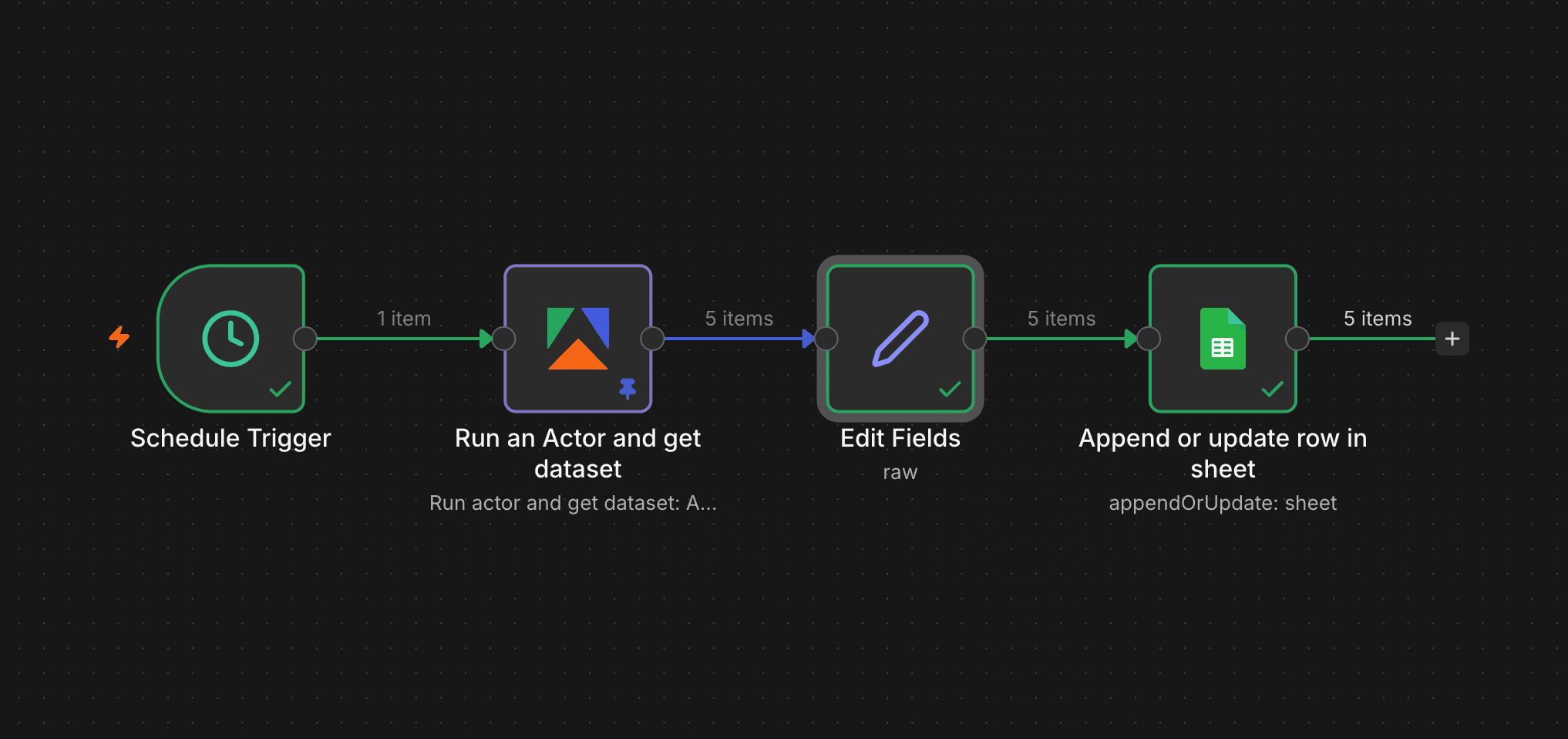
Step 1:選擇 Instagram Scraper
到 Apify Store 搜尋「Instagram」,官方的 apify/instagram-scraper 蠻穩定的:
| 可爬取類型 | 說明 | 限制 |
|---|---|---|
| posts | 貼文內容 | 每帳號最多抓 20 筆(免費方案) |
| comments | 貼文留言 | 每篇最多 50 則 |
| details | 帳號詳細資訊 | 粉絲數、追蹤數、簡介 |
| reels | 短影片 | - |
同一個平台(例如 Instagram)會有多個不同的 Actor,怎麼選?
- 看評分和使用人數:越多人用通常越穩定
- 看價格:有些 Actor 按筆數計費,有些按執行時間
- 看維護頻率:最近更新日期越近越好(社群平台常改版)
- 先用免費額度測試:跑幾次看回傳資料是否符合預期
官方 Actor(帳號名稱是 apify/)通常比較穩定,但價格可能較高。
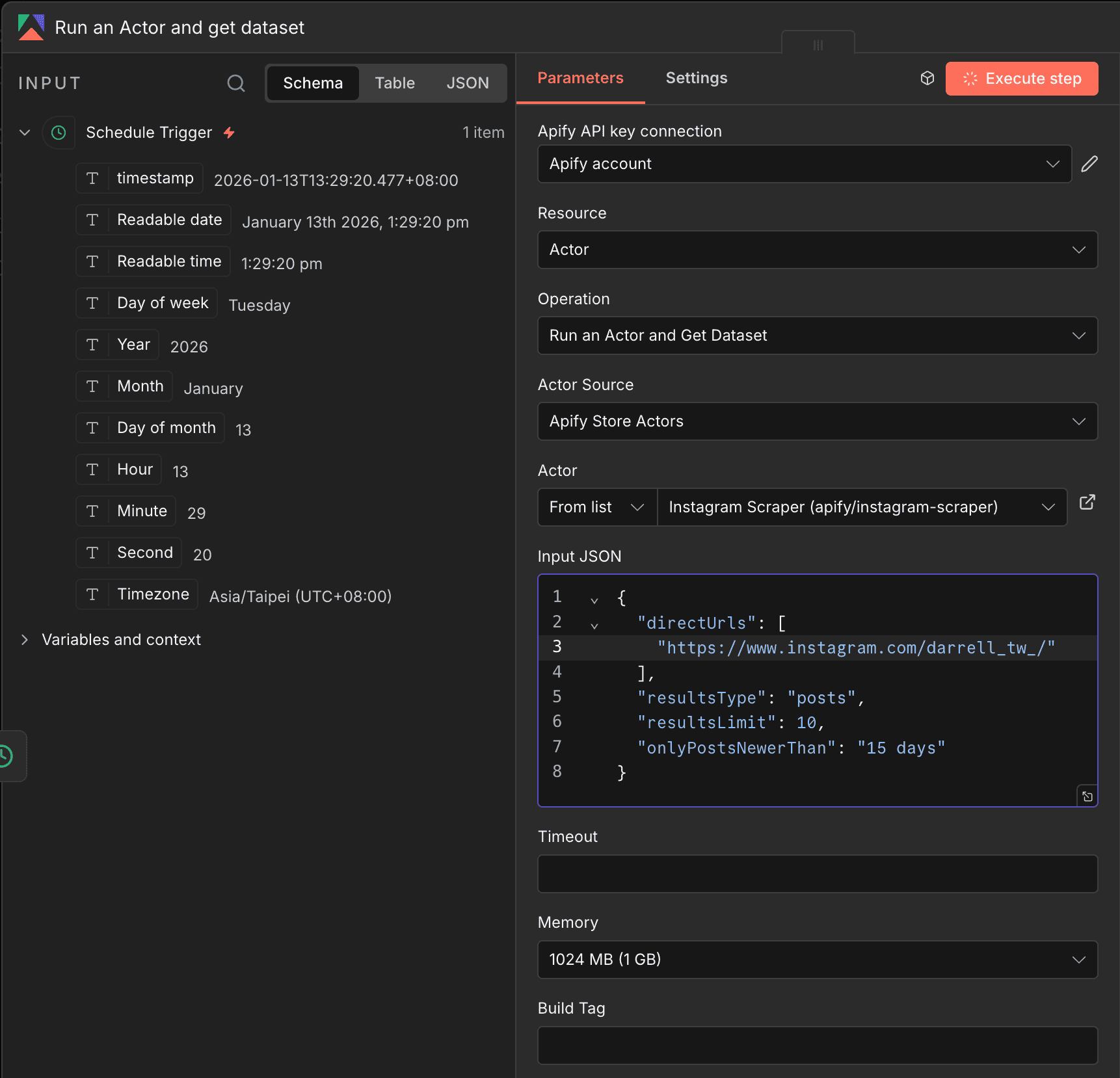
Step 2:設定 Apify 節點
選擇 Run Actor and get dataset items,填入以下參數:
Actor: apify/instagram-scraper
追蹤特定帳號的設定,直接複製下面這段貼到 Input JSON 欄位:
1 | { |
把 competitor1 換成你想追蹤的帳號名稱就好。
Step 3:用 Set Node 整理資料
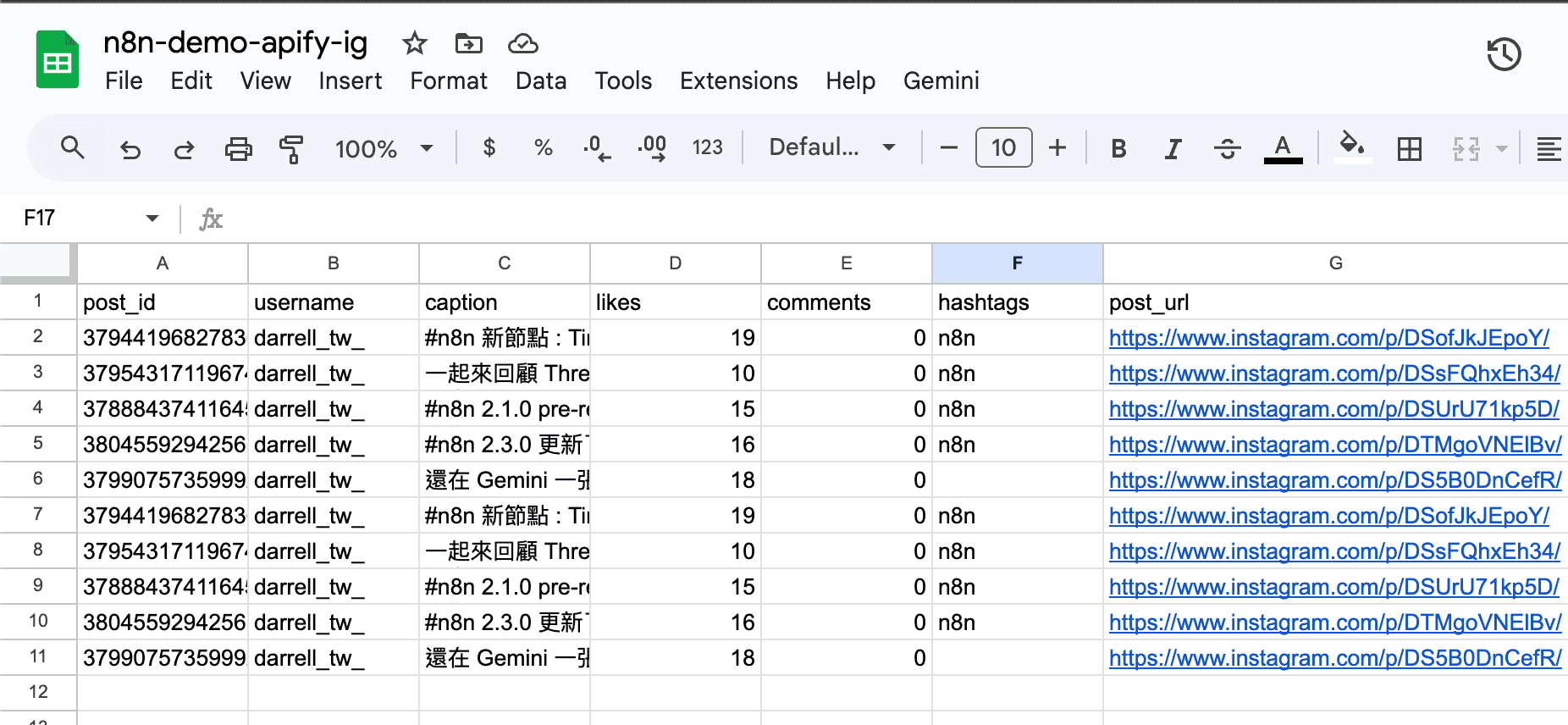
Instagram Scraper 回傳的資料欄位很多,用 Set Node 把需要的欄位整理出來。
直接照著下面的截圖設定就好,不需要懂程式:

設定好之後,每筆資料會變成這樣的格式:
- 貼文 ID
- 帳號名稱
- 貼文內容(前 200 字)
- 按讚數
- 留言數
- Hashtag
- 貼文網址
- 發布時間
如果 Instagram 的按讚數顯示 -1,代表該用戶隱藏了按讚數,這是正常的。
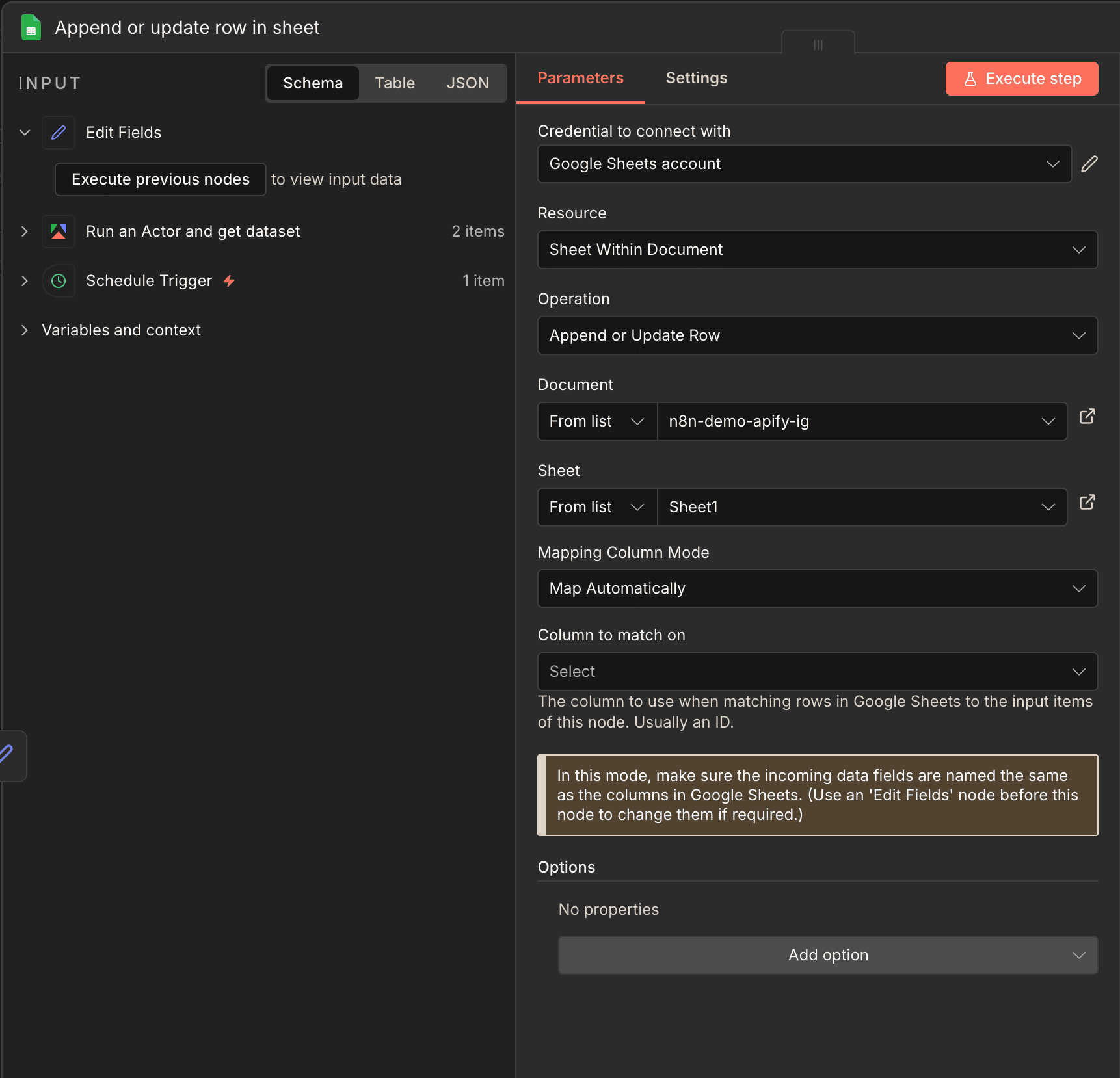
Step 4:寫入 Google Sheets
最後用 Google Sheets 節點的 Append Row(新增一列)把資料寫進去。
實測效果和費用:
apify/instagram-scraper 的價格是 $2.7 美元/1000 筆資料
所以每個月就算搜集到一千筆貼文,也都還沒超過免費額度。
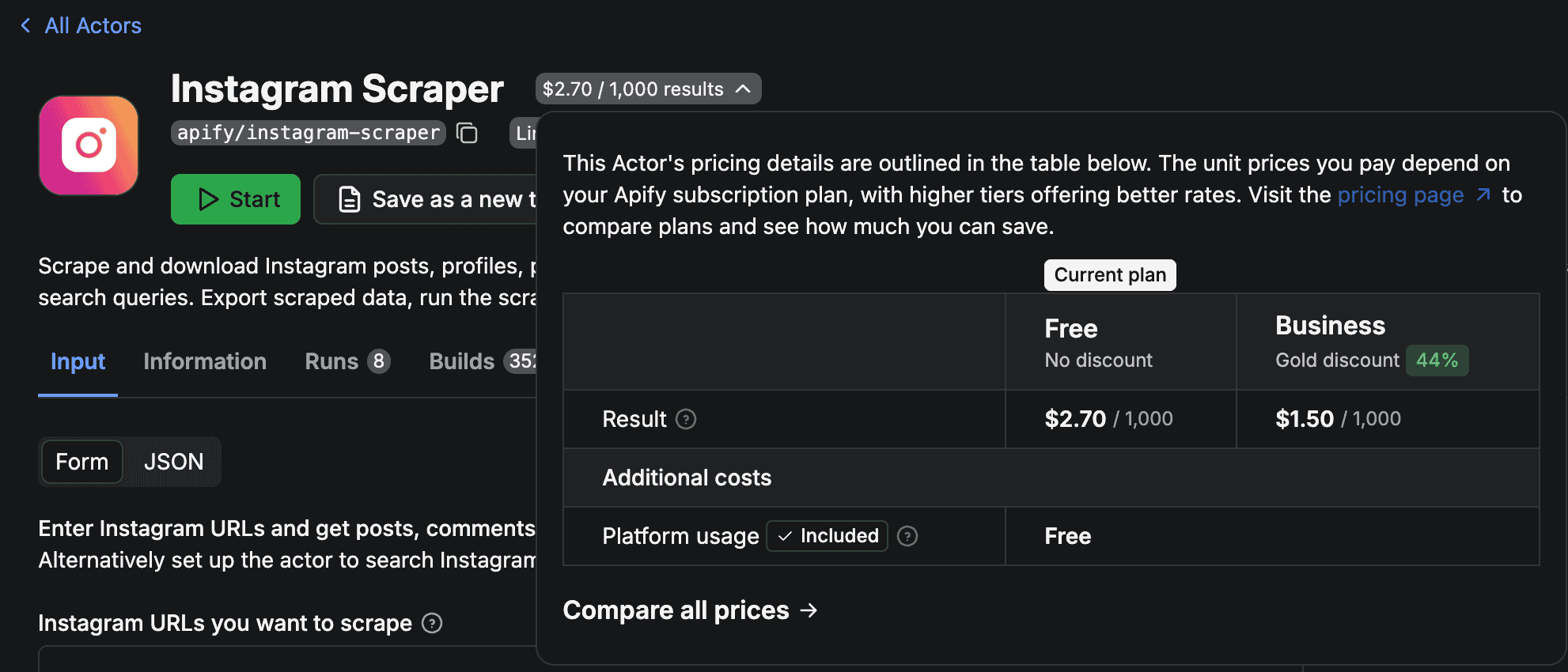
如果你需要大量爬取,可以這樣省錢:
- 減少不必要的欄位:在 Actor Input 中設定
fields只取需要的資料 - 設定合理的 resultsLimit:不要貪心一次爬太多
- 避免重複爬取:用 n8n 的 If 節點 檢查是否已經爬過
- 選擇便宜的 Actor:同樣功能的 Actor 價格可能差 2-3 倍
什麼時候不該用 Apify?
Apify 看起來很好用沒錯,但還是想分享有些不適合的場景:
免費額度 $5 聽起來蠻多的,很多時候免費額度綽綽有餘。
但如果是商用想要爬大量的數據,就得思考付費的方案是否划算?
| 使用頻率 | 月費估算 | 免費額度可用 |
|---|---|---|
| 每天 50 筆 | ~$4 | ok |
| 每週 50 筆 | ~$0.54 | ok |
| 每天 200 筆 | ~$16 | 需付費 |
有官方 API 就別硬爬
爬取社群平台資料有法律風險。Instagram、TikTok 的服務條款都明確禁止未授權的資料抓取,商業用途前建議先確認合規性。
實際建議:
- 個人研究、學習用途:風險較低
- 商業用途:建議諮詢法律顧問
- 爬取自己的帳號資料:用官方 API 更安全
我自己使用 Apify 都是想自動化參考別人的內容時才會使用。
如果是拿來爬取自己的數據,其實就不需要 Apify
原因是大部分的社群平台都會有 API 可以抓去自己的數據
這時就會盡量用官方 API 來抓取,穩定度來說會好很多!
常見問題
Run Actor and get dataset items:會等 Actor 跑完,直接拿到資料,初學者推薦用這個Run Actor:只負責啟動,需搭配 Trigger 或另外撈取 Dataset如果你的 Actor 執行時間很長(超過 5 分鐘),才需要考慮用 Run Actor + Trigger 的組合。
適合:靜態網頁、部落格、新聞網站
不適合:需要登入、有反爬機制、大量 JavaScript 渲染的網站
如果要爬社群平台,還是建議用專門的 Actor。
相關文章推薦


總結
爬蟲一直是一個很大的學問,厲害的工程師們可以寫出各種花式的爬蟲程式。
但是 Apify 這個服務把爬蟲這件事簡化很多。
現在我們就挑選適合的 Actor 後測試幾輪,就能知道是不是真的能滿足我們的需求。
缺點有幾個:
- 部分 Actor 價格很貴,甚至是有訂閱的費用(每月 $20 美金等等)
- 有時候 Actor 參數設定沒問題,但跑出來的結果就是不符合我們的預期,這時只能換換看其他 Actor
整體來說還是相當推薦,畢竟在 AI 時代我們就是希望用最快最簡單的方式來取得資料
有任何 Apify 相關問題歡迎在下方留言